source: 小红书 url: https://www.xiaohongshu.com/discovery/item/6a08772a0000000006035141?app_platform=ios&app_version=9.25&share_from_user_hidden=true&xsec_source=app_share&type=normal&xsec_token=CBFwtJ_agIAv4wiLqJR_CueisVDlbtgObhe0jfuDl_qLI=&author_share=1&xhsshare=WeixinSession&shareRedId=ODY7Nzs8ND02NzUyOTgwNjY0OTc5Sz85&apptime=1779517290&share_id=d8e4bd41adbc49dba33ef5ba59b0a68e saved: 2026-05-23 14:22:07
id: 706c67a4-6357-4c33-9775-0afa52a1ab35
作者: 方舟解刨所
发布/编辑时间: 2026年05月16日 13:54
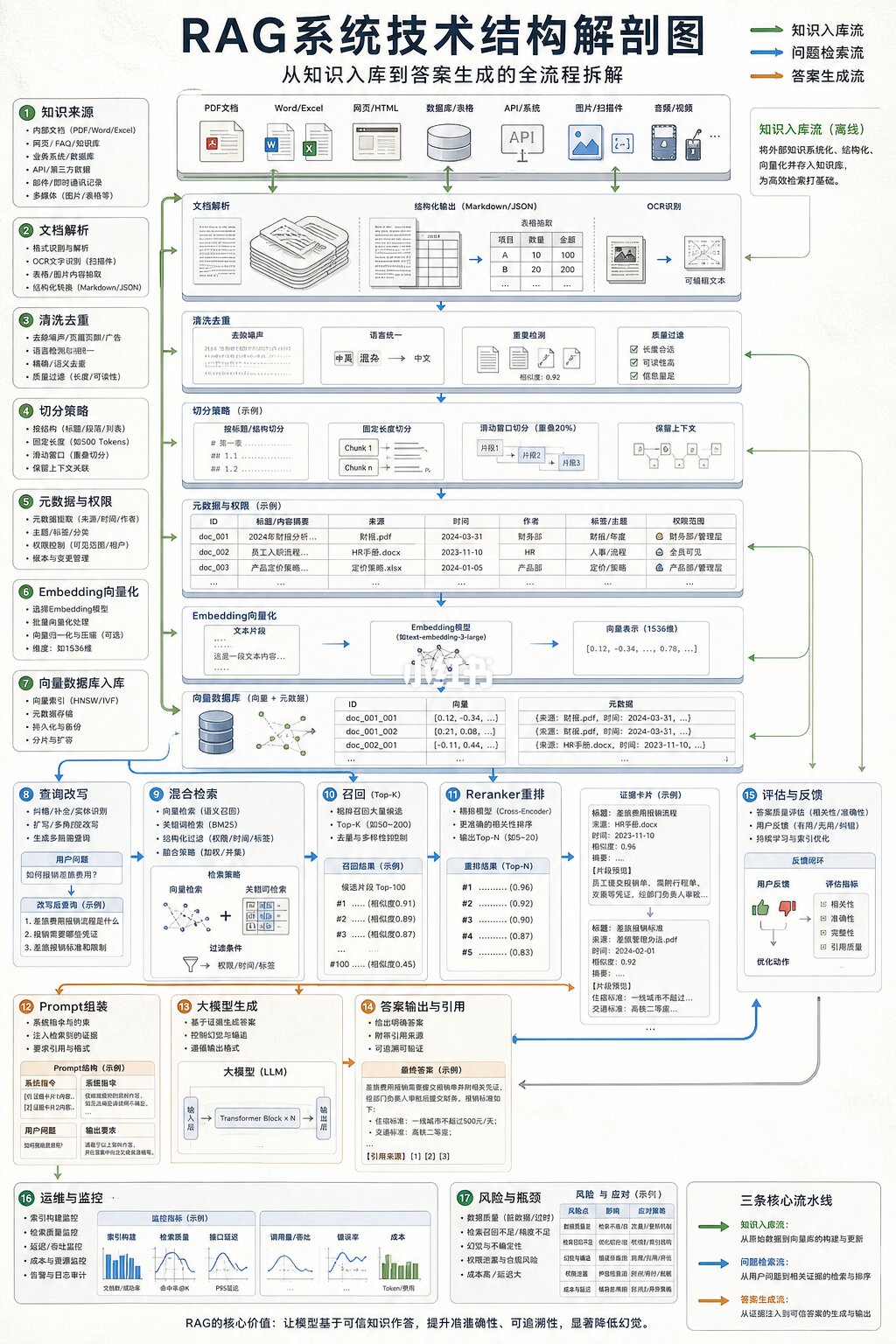
RAG经常被说成“给大模型接一个知识库”。
但真正能用的RAG系统,远不止一个向量数据库。
第一层是知识来源。企业文档、PDF、网页、数据库、工单、代码仓库,都可能进入系统。但原始资料不能直接喂给模型,必须先解析、清洗、切分、去重,并加上元数据和权限标记。
第二层是向量化。文档片段会经过Embedding模型,变成机器能比较相似度的向量。这里决定了系统能不能理解“语义相近”,而不是只做关键词匹配。
第三层是索引和检索。用户提问后,系统会把问题也转成向量,再从知识库里召回相关片段。很多成熟系统还会做混合检索:语义检索 + 关键词检索 + 元数据过滤。
第四层是重排。召回不等于准确,Reranker会重新判断哪些证据最相关,把噪声片段筛掉,再交给大模型。
第五层是Prompt组装。用户问题、系统指令、检索证据、引用来源和回答格式,会被拼成一个上下文,让模型基于资料生成答案。
RAG的价值,是让大模型不只依赖训练时记住的知识,而是能连接企业自己的实时资料。
它的瓶颈也很真实:文档切分不好会召回失败,Embedding不准会语义跑偏,权限控制不严会泄露数据,证据质量差会让模型一本正经地胡说。
所以RAG不是“接资料”,而是把知识加工成可检索、可引用、可治理的外部记忆系统。
你觉得RAG最难的是检索准确,还是企业数据治理?
#人才地图构建 #智能化转型 #项目管理 #人工智能发展 #库里 #数字化时代 #大模型
内容效果不满意?点此反馈