字幕
 评测级别
评测级别
为什么你在本地测试的RG应用评分很高
但一上线业务方还是觉得效果不好呢
原因很简单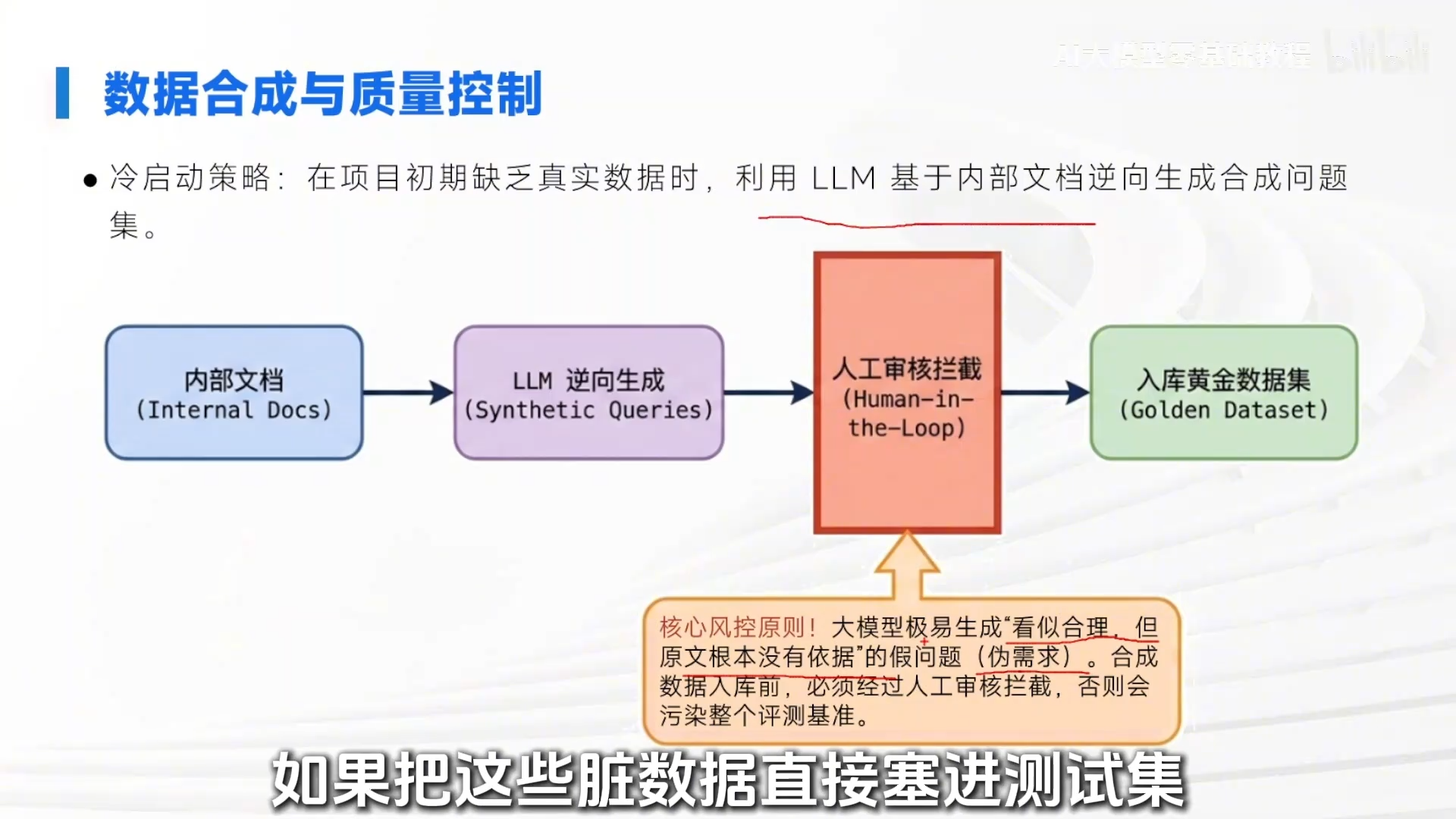

总结:企业级 RAG 评测与诊断指南
本文系统性地介绍了企业级 RAG(检索增强生成)系统的评测与诊断方法,强调告别传统的“黑盒”思维,建立基于分层拆解和交叉指标的系统性诊断体系。
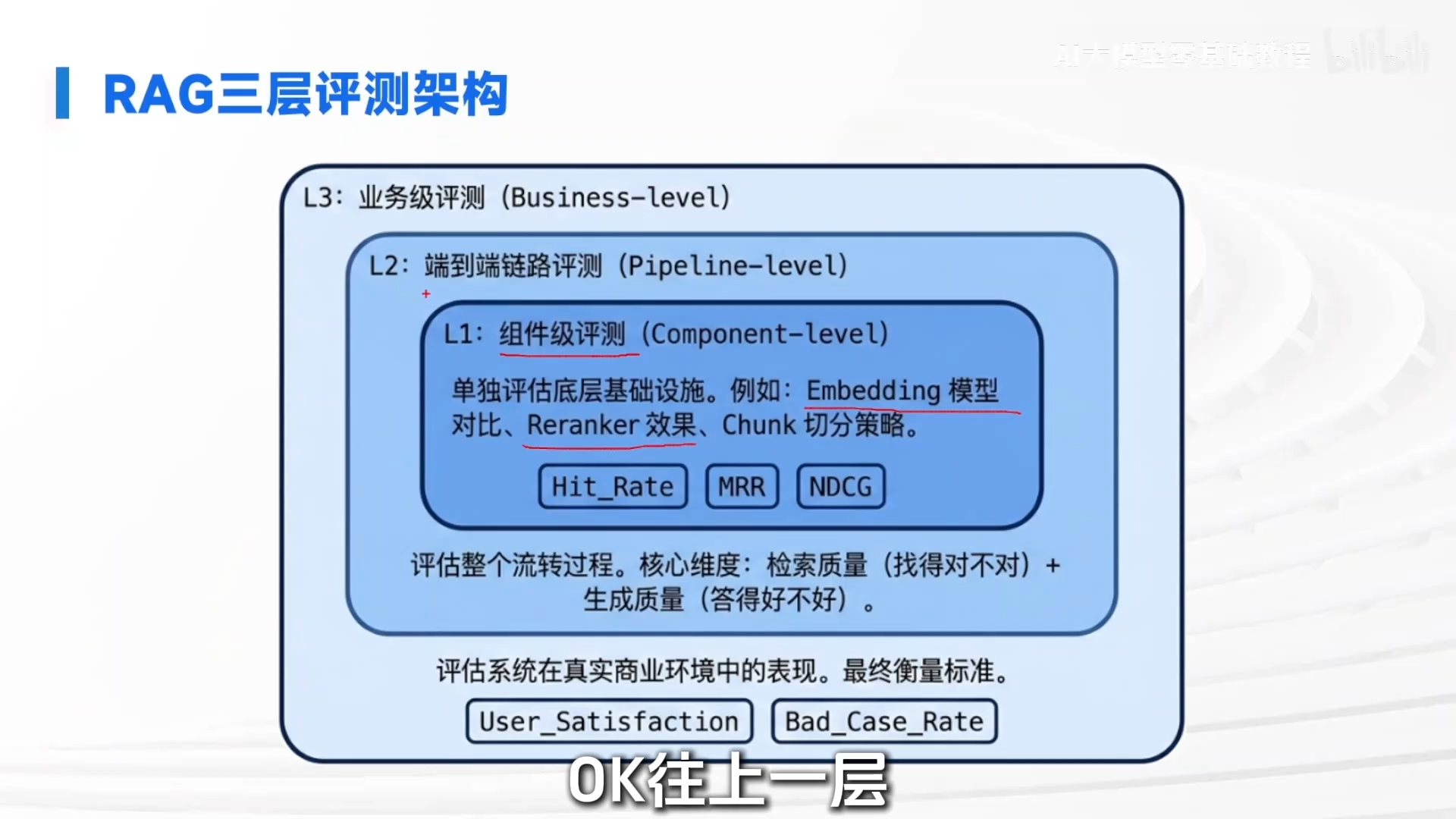
一、 分层评测理念(L 1-L 3)
传统 NLP 将系统视为黑盒,只评估最终答案,无法定位问题根源。RAG 系统需采用“听诊器”思路,将流程拆解为检索、上下文组装、模型生成等节点进行监测。
- L 1: 组件级评测:测试底层组件性能,如 Embedding 模型、Reranker 效果。关注硬核检索指标(如命中率)。
- L 2: 端到端链路评测:评估整个流水线的顺畅度。核心关注两个问题:检索是否准确(找的对不对)、生成是否可靠(答得好不好)。
- L 3: 业务级评测:衡量最终业务价值,如用户满意度、线上 Bad Case 触发率。技术指标再好,若用户觉得没用,则毫无价值。
二、 核心量化指标(检索与生成)
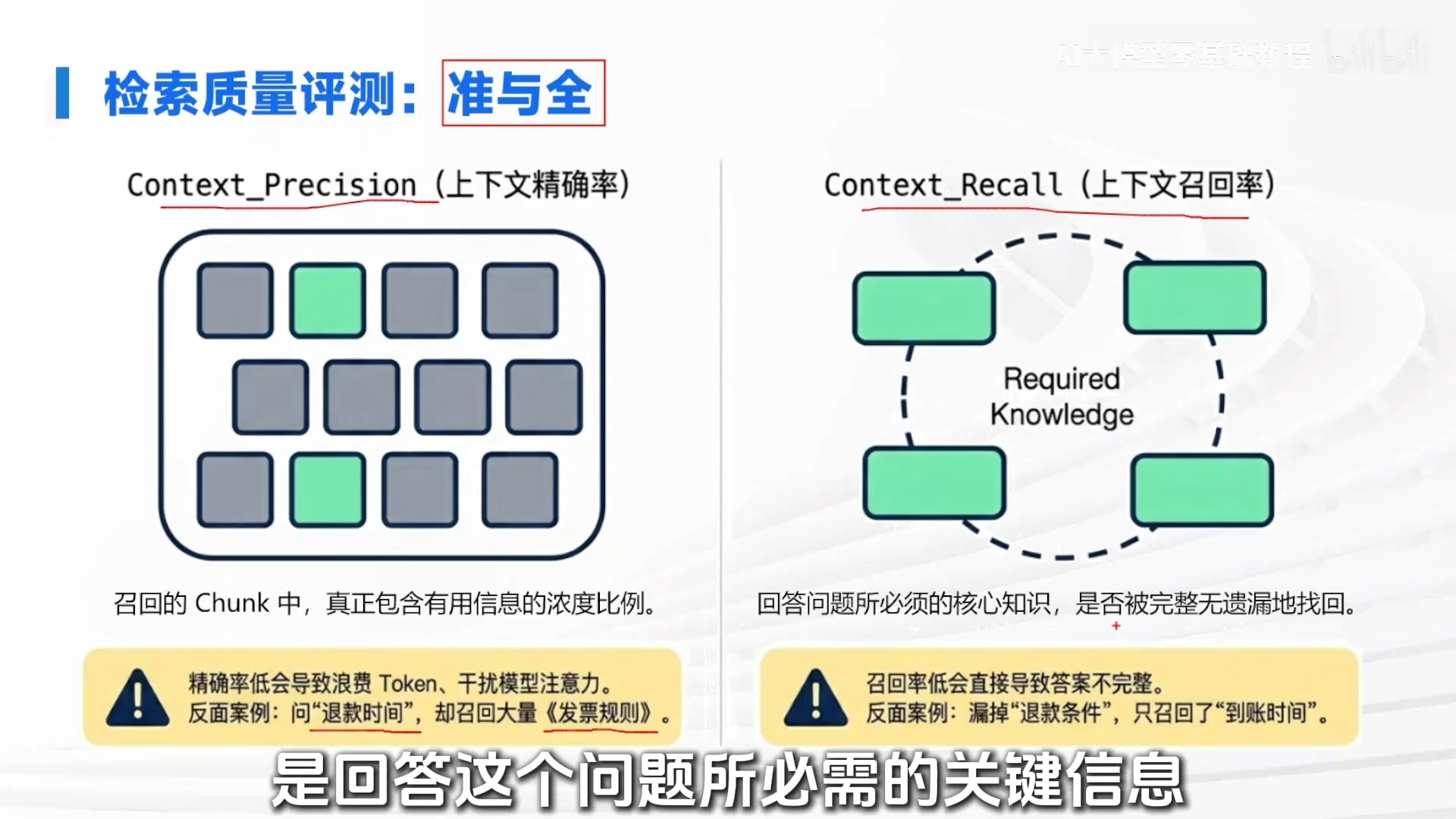
1. 检索阶段:追求“准”与“全”
- 上下文精确率:衡量检索到的文本块(Chunks)中有多少是真正有用的“干货”。低精确率会导致浪费 Token 且干扰大模型。示例:用户问“退款多久到账”,系统却捞回了“发票开具规则”,这就是精确率低。
- 上下文召回率:衡量回答问题所需的关键信息是否被完整找回。低召回率会导致答案不完整。示例:用户问复合问题“退款条件和到账时间”,系统只找回“到账时间”,漏掉“退款条件”,就是召回率低。
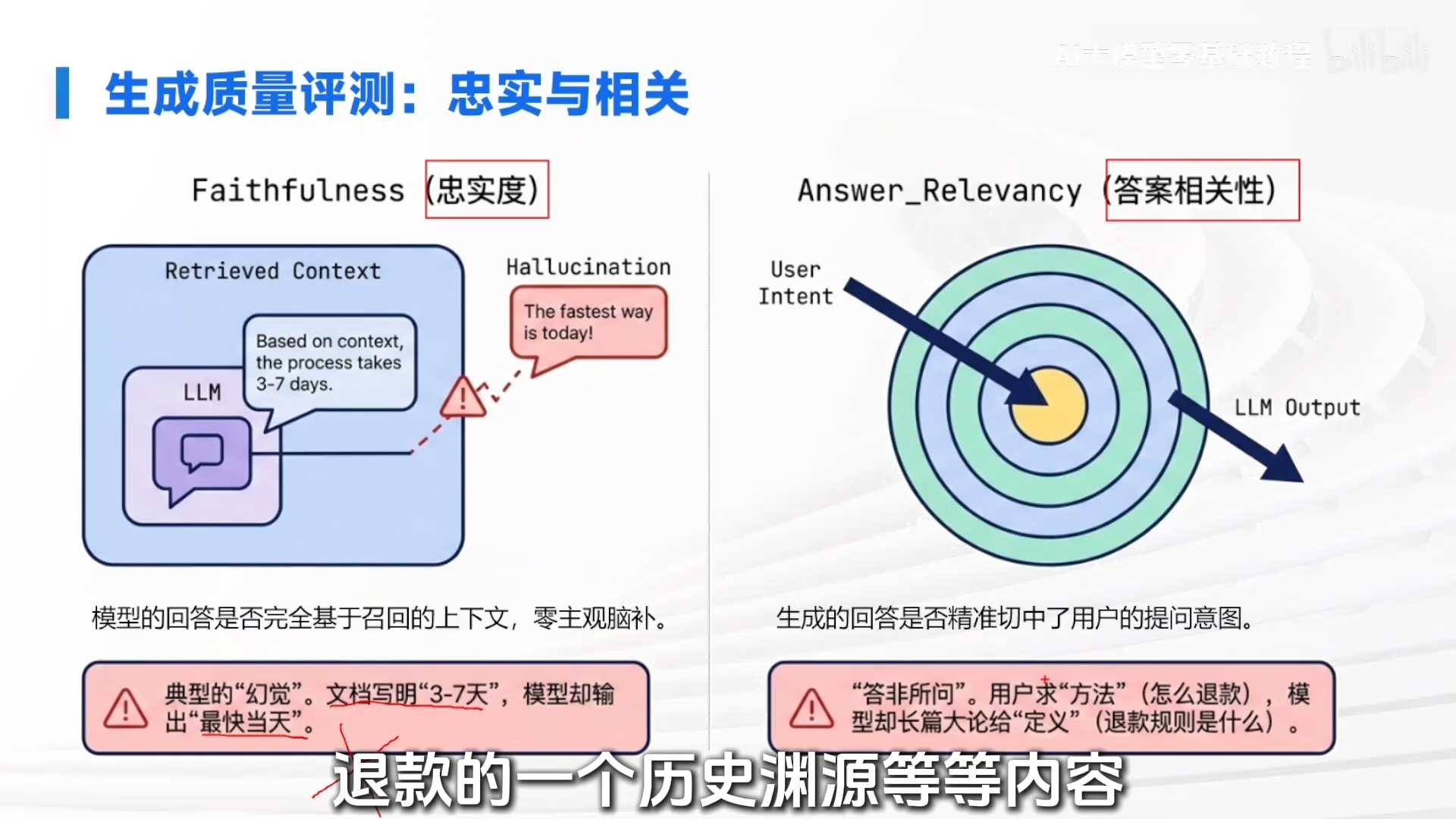
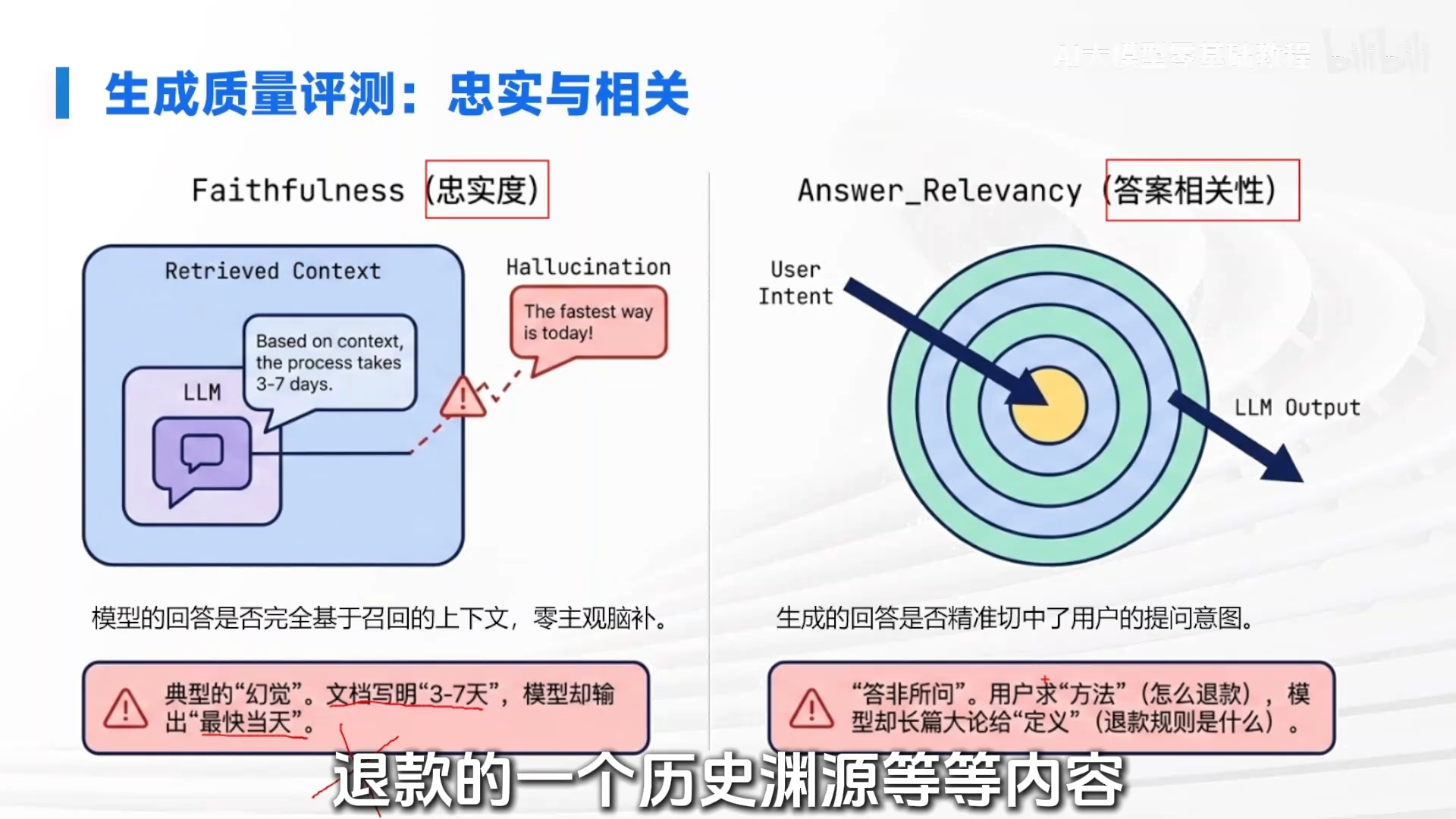
2. 生成阶段:评估“忠”与“切”
- 忠实度:衡量大模型是否严格基于提供的参考资料回答,不自行编造。低忠实度即“幻觉”。示例:资料写“退款需 3-7 个工作日”,模型回答“最快当天到账”,就是不忠实。
- 答案相关性:衡量回答是否精准切中用户真实意图,而非答非所问。低相关性导致“事实正确但无用”。示例:用户问“如何申请退款”,模型却解释“什么是退款规则”,就是相关性差。
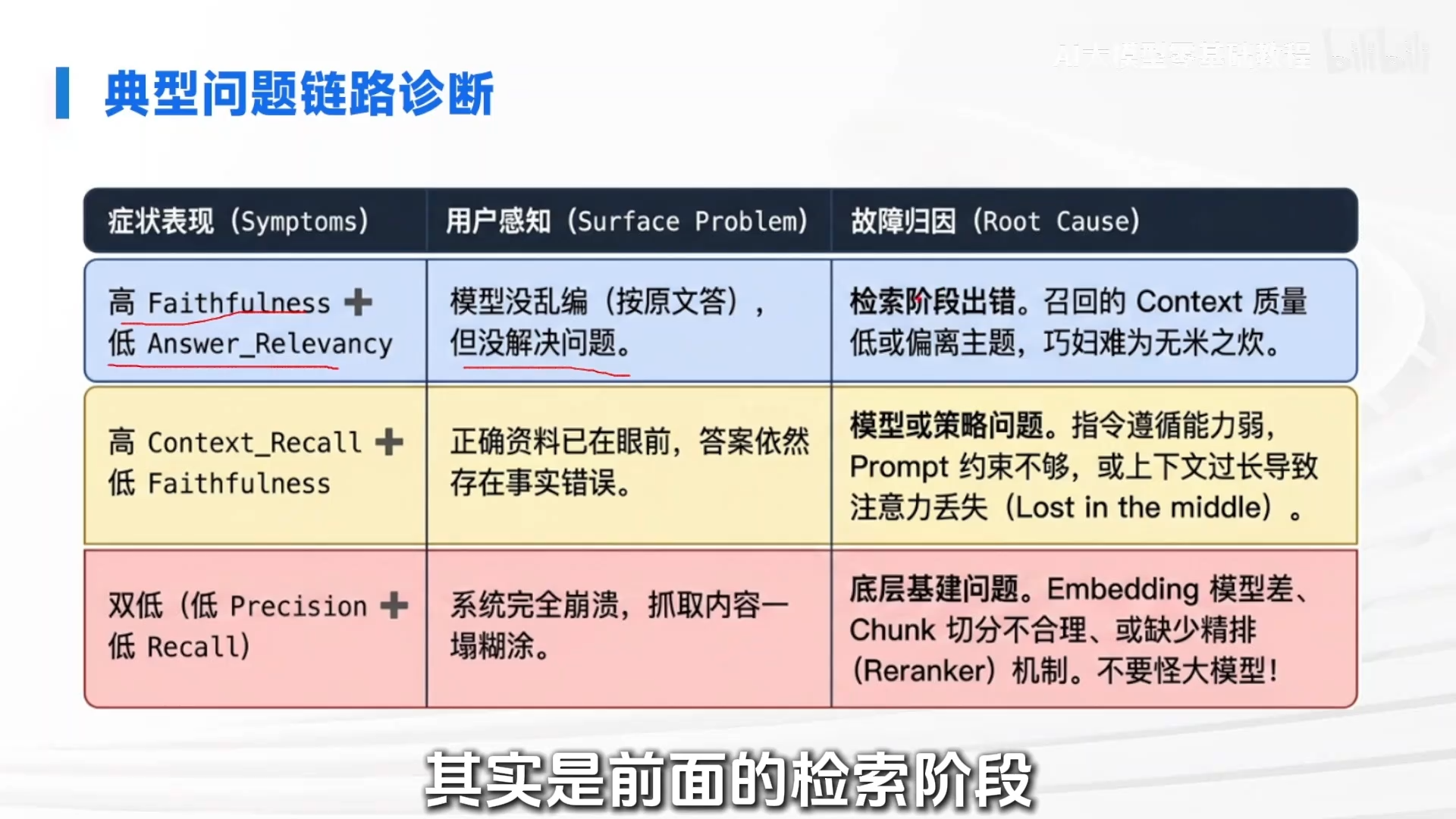
三、 基于交叉指标的系统故障归因(难点详解)
单一指标无意义,需通过高低分组合“交叉诊断”,精准定位系统薄弱环节。这与看验血报告类似,单看一项正常,但几项交叉分析就能发现病根。
难点: 难点在于理解指标之间的因果链。例如,忠实度高但相关性低,问题不在模型,而在检索。反之,召回率高但忠实度低,问题则出在模型。这需要工程师具备系统性的思考能力,而非只关注最终分数。
- 场景一:高忠实度 + 低相关性
- 表象:模型很听话,没有瞎编,但回答不能解决用户问题。
- 归因:检索召回质量太低。模型拿到了与问题无关的资料,被“带偏”了,只能基于错误信息重复。
- 场景二:高召回率 + 低忠实度
- 表象:正确的资料已找到并喂给模型,但模型依然答错或产生幻觉。
- 归因:模型端或策略端问题。可能原因:1)大模型本身能力弱;2)Prompt 约束不够强;3)参考文本过长,模型读取时“注意力丢失”,导致忘记前面内容。
- 场景三:低精确率 + 低召回率
- 表象:系统表现差,检索内容一塌糊涂。
- 归因:底层基建问题。不要急于换模型,问题可能在:1)Embedding 模型选型不当;2)文本分块策略太粗暴;3)缺少 Reranker 等精排机制。这是地基没打好。
四、 工程落地与业务闭环
1. 构建黄金数据集(“手里要有粮”)
- 三要素:1)真实用户 Query;2)专家标注的 Ground Truth(标准答案);3)标准答案所依据的源文档片段(Reference Chunks)。
- 冷启动:可先用大模型对内部文档反向生成 QA 对。
- 难点:数据合成存在“自嗨”风险。大模型可能生成看似合理但原文无依据的“假问题”(伪需求),必须经过人工审核拦截,否则会污染评测标准,导致评测结果不可信。
2. 自动化工具选型
- 起步阶段:推荐 VEGAS,轻量、开箱即用,可快速跑分。
- 深水区/企业级:推荐 DeepEval 或业界 RAG 四件套,工程化程度高,适合接入 CI/CD 流水线,进行回归测试。
- 线上监控:推荐 TruLens 或 LangSmith,适合上线后记录链路数据,分析单次请求耗时和节点瓶颈。
3. 回归业务指标
- 用户反馈:赞踩比例、用户追问率(追问率高表示系统未能一次解决问题)。
- 运营风控:线上 Bad Case 触发率。
- 核心 KPI:客服转人工率。这是衡量 RAG 系统是否真正降低人力成本的关键指标。
总结三步走:
- 看准指标:用检索的“准/全”和生成的“忠/切”来衡量。
- 交叉诊断:组合高低指标,定位问题根源。
- 回归业务:所有技术努力必须最终落到真实的业务数据上。
进阶思考题
- 归因反转题:如果系统出现“低忠实度 + 低相关性”但“高精确率 + 高召回率”的情况,你认为最可能的原因是什么?应该如何排查?(提示:跳出检索和模型,思考 Prompt 设计或用户意图识别。)
- 数据污染题:视频中提到大模型合成数据会产生“伪需求”。请你设计一个具体的人工审核流程,在资源有限的情况下,如何高效地识别并过滤掉这些“自嗨”样本?可以给出 2-3 个判断依据。
- AB 测试题:你作为技术负责人,需说服业务领导上线一个新 RAG 系统。除了“客服转人工率”,你还会设计哪些业务 KPI 来证明新系统的价值?请解释每个指标背后的逻辑。
- 极端场景题:假设你的 RAG 系统在线上出现“高相关性 + 高忠实度”但“用户追问率极高”的矛盾现象。请分析可能的原因,并设计一个实验来验证你的猜想。
- 指标矛盾题:上下文精确率和上下文召回率在优化时常常是矛盾的(提升召回率可能会引入噪音,降低精确率)。请结合 Reranker 模型,设计一个策略来平衡这两个指标,并说明你如何验证策略的有效性。