source: 小红书 url: https://www.xiaohongshu.com/discovery/item/6a01fcf500000000060301bb?app_platform=ios&app_version=9.25&share_from_user_hidden=true&xsec_source=app_share&type=normal&xsec_token=CBJMH705lwKuuZ2Ku1tmkRHW03jiGRFZhe_RdU2-9r8J0=&author_share=1&xhsshare=WeixinSession&shareRedId=ODY7Nzs8ND02NzUyOTgwNjY0OTc5Sz85&apptime=1779194881&share_id=c3ddf5c272b9492ebdef3594973fef05 saved: 2026-05-19 20:48:32
id: ad442537-abfb-45b6-8d16-4b802ff281d8
作者: AI-Frontiers
发布/编辑时间: 2026年05月11日 15:59
家人们,Transformer的注意力机制,这次真的被我啃透了!
😭 咱们的目标不止于"How",更要搞懂"Why"!💡
它到底是怎么让句子里的词"互相看见"的?跟我来,包懂!👇
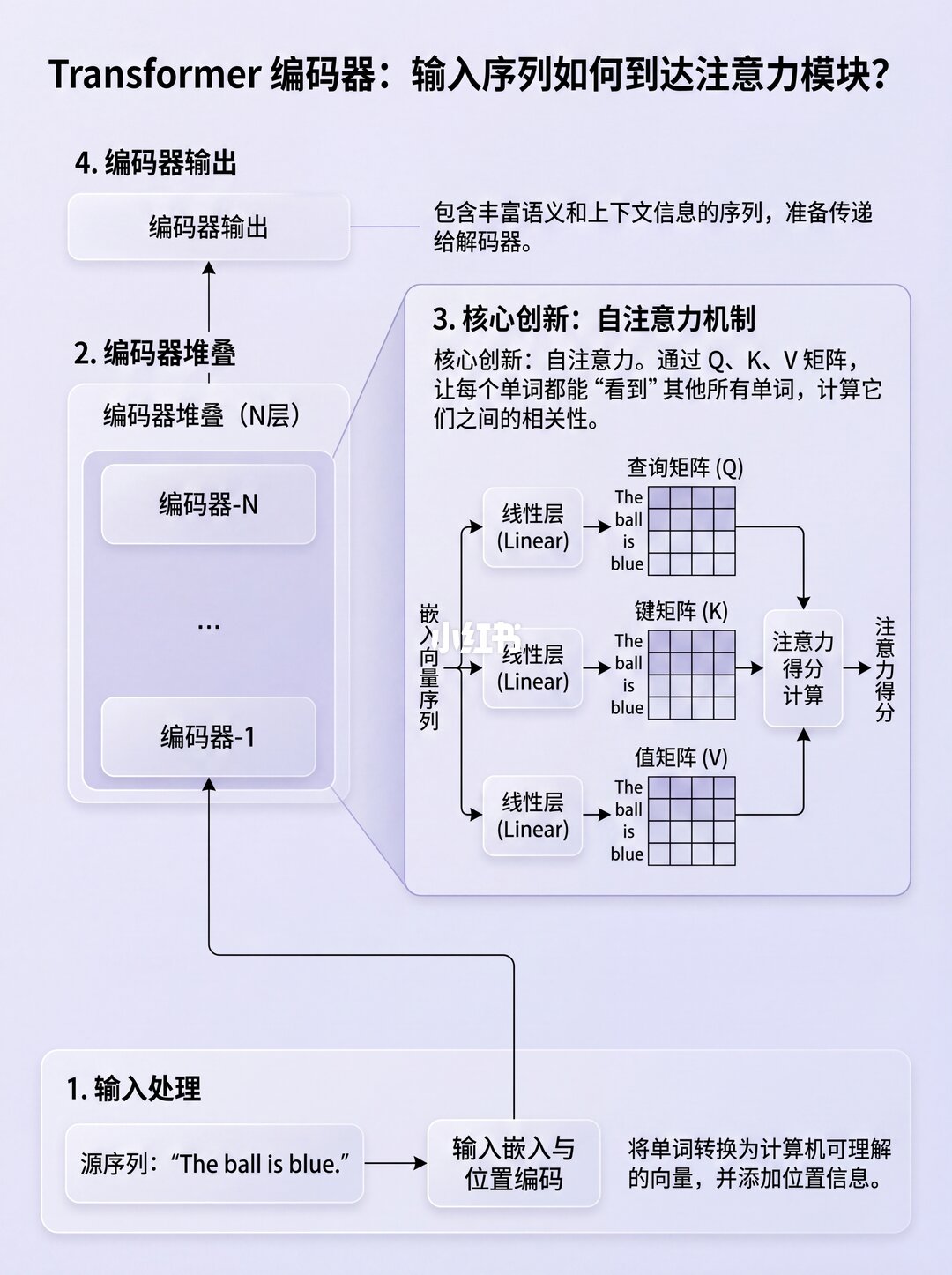
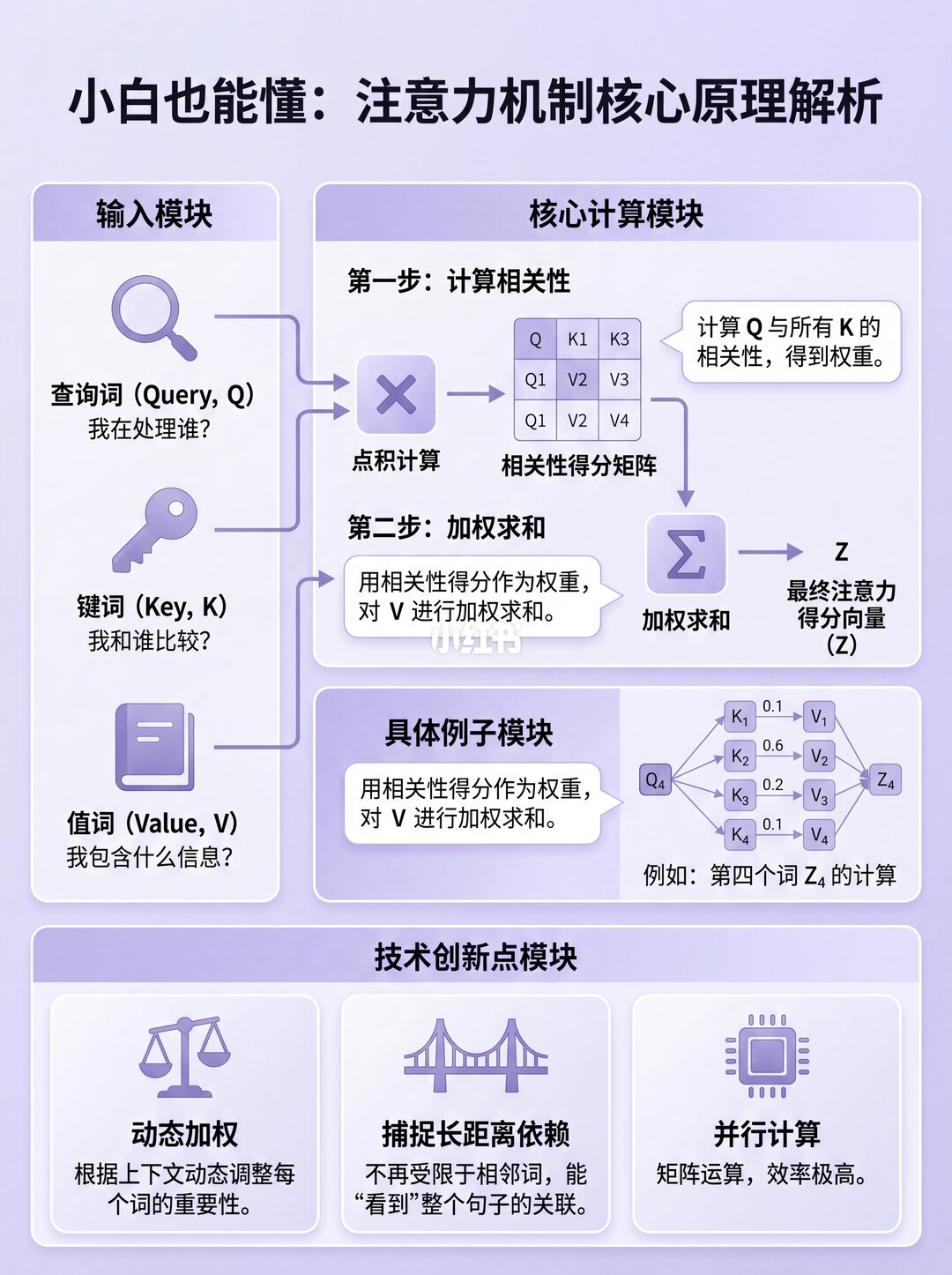
✨ 输入序列的"变身"之旅
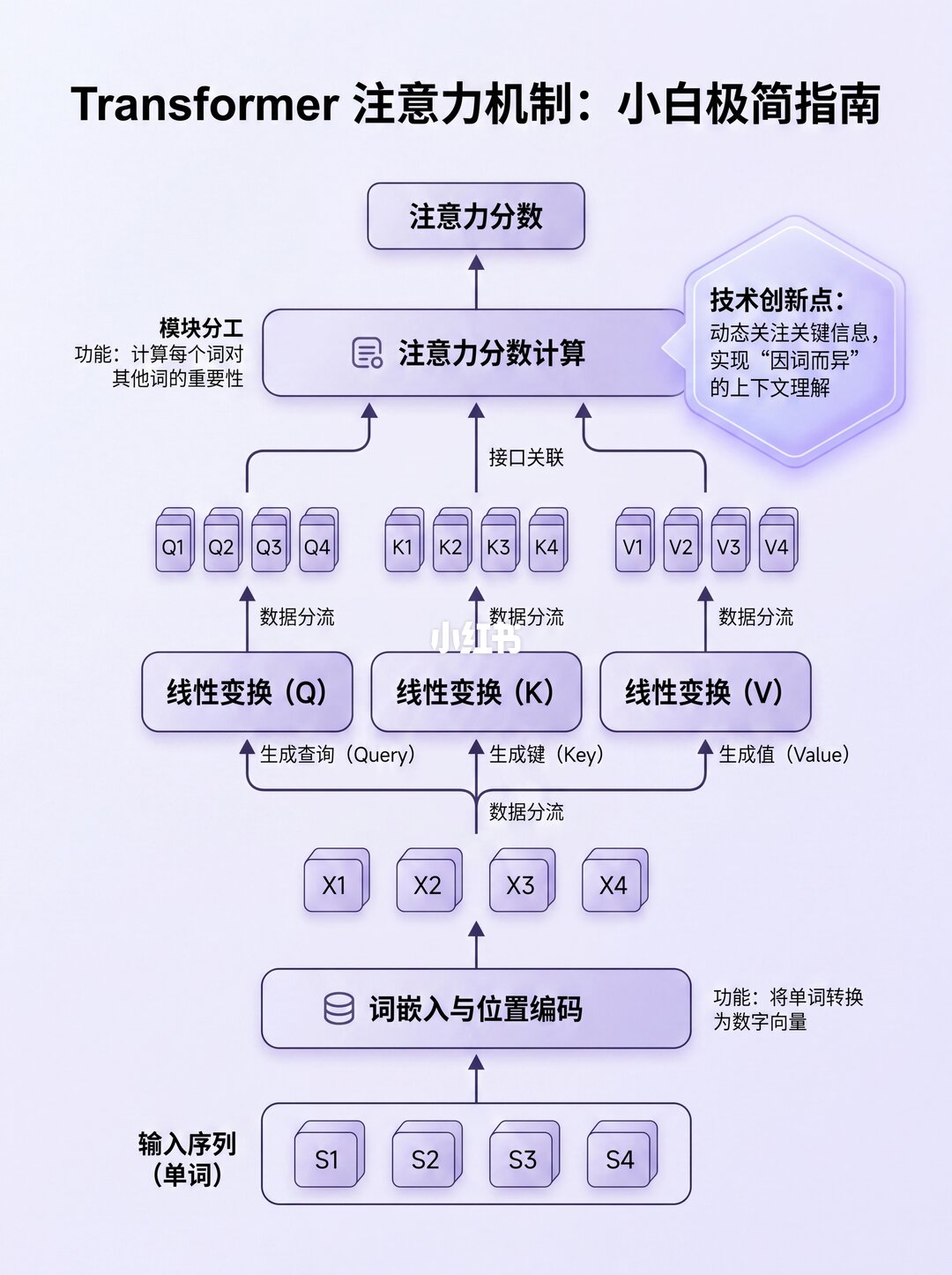
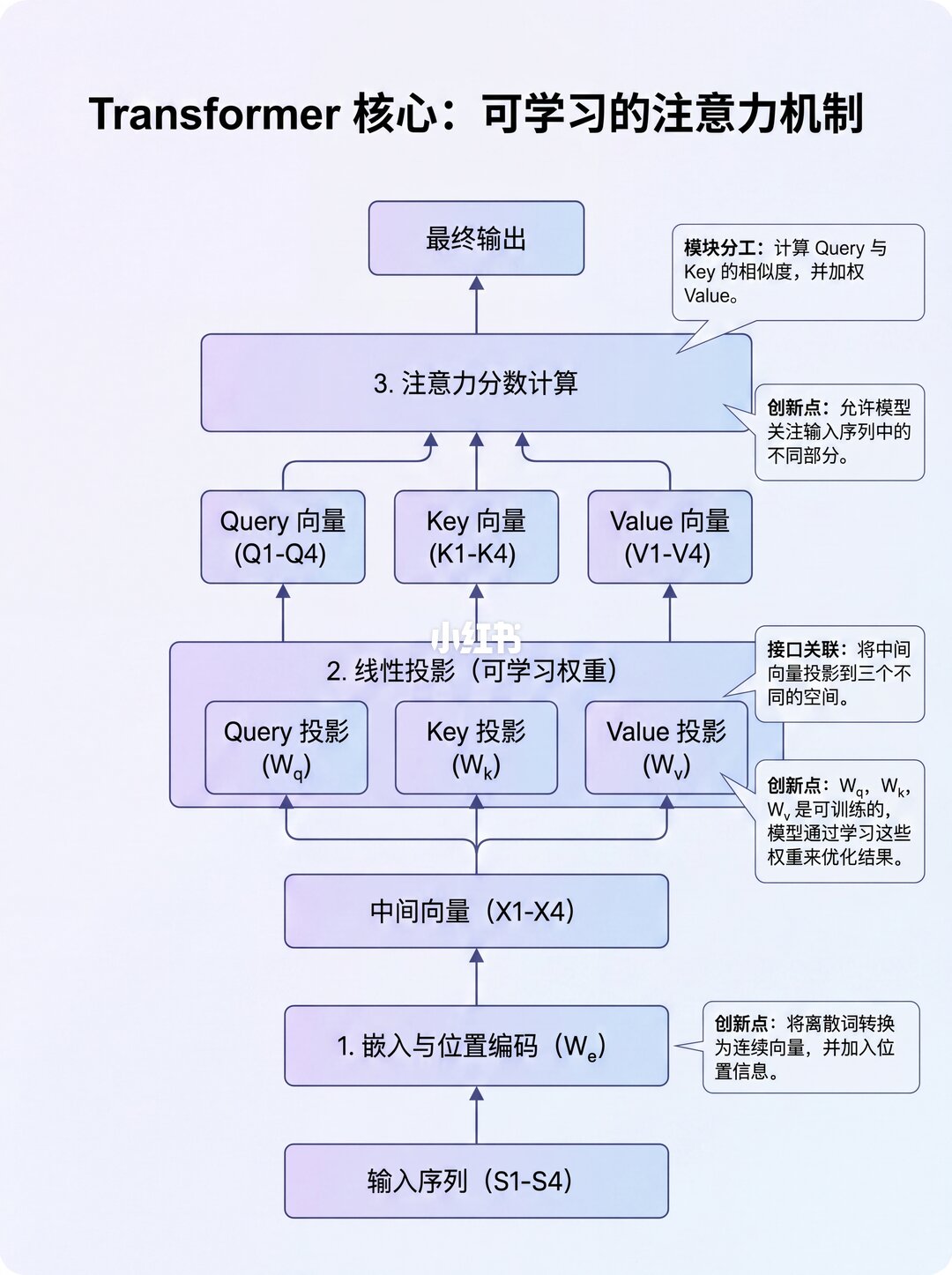
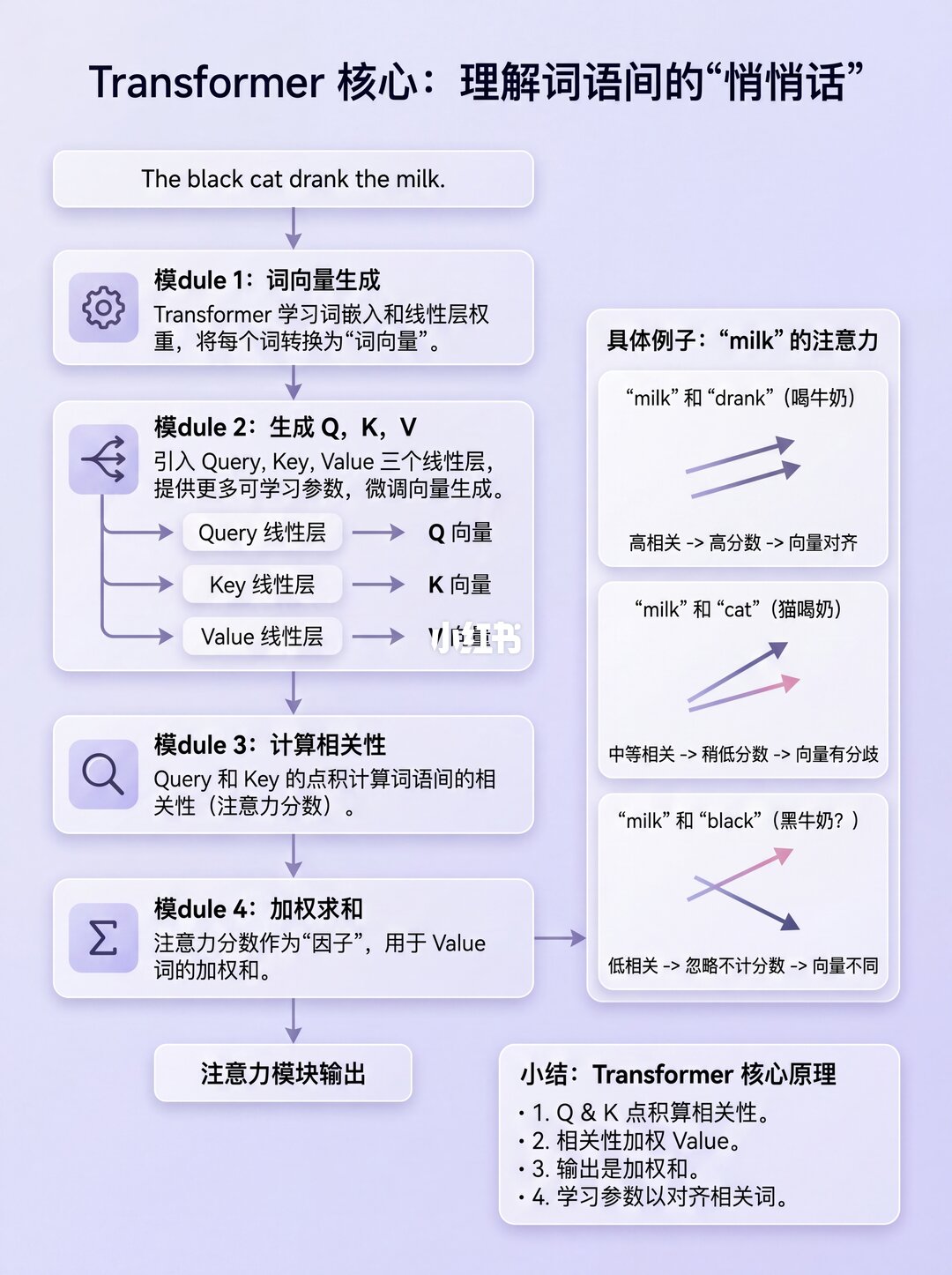
源序列(比如"The ball is blue")先经过嵌入和位置编码,变成词向量。
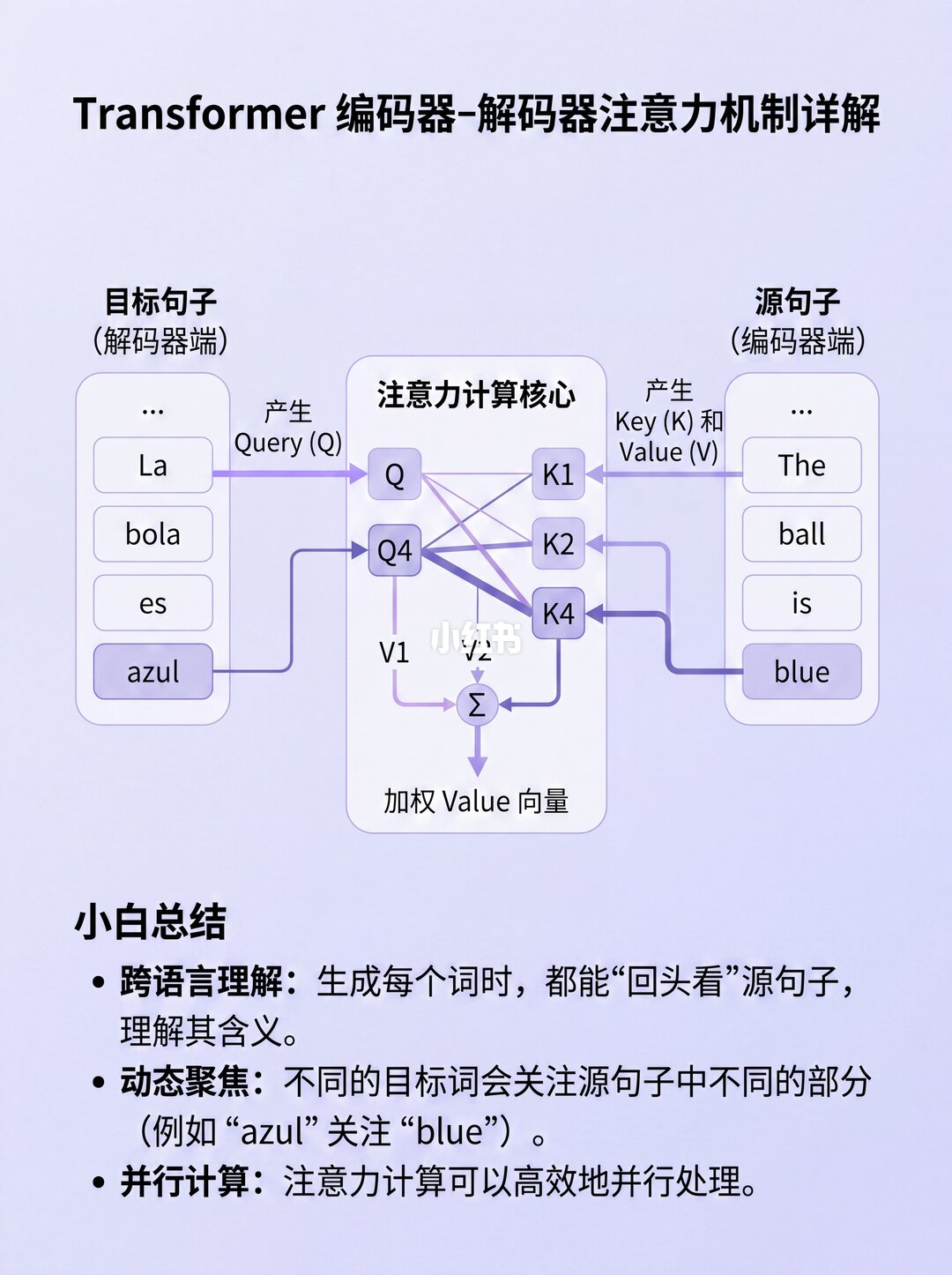
接着进入编码器的注意力模块,关键一步来了!每个词向量会经过三个线性层,变身成三个矩阵:
🔹 查询矩阵 (Q)
🔹 键矩阵 (K)
🔹 值矩阵 (V)
记好它们,后面要考!📝
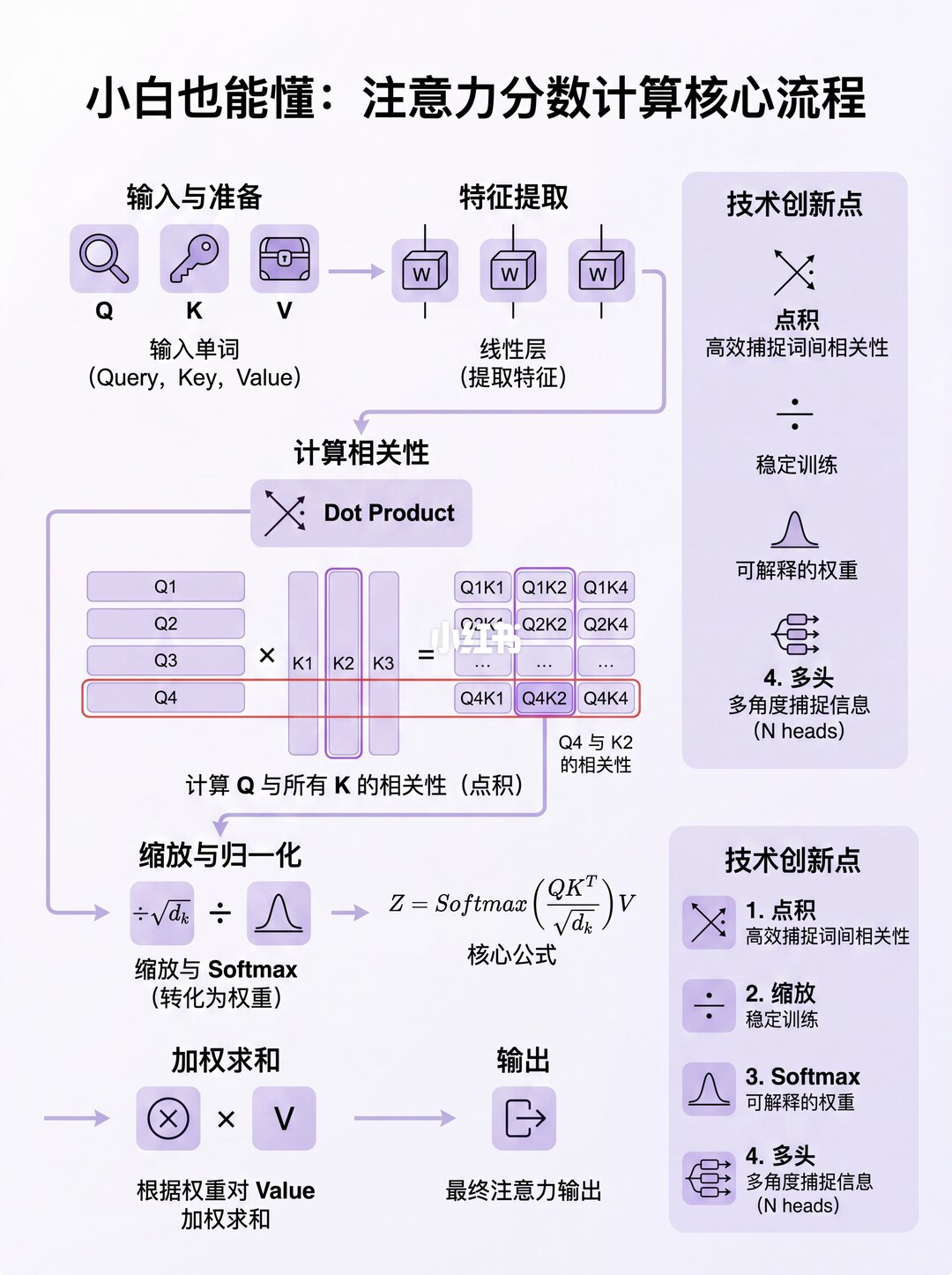
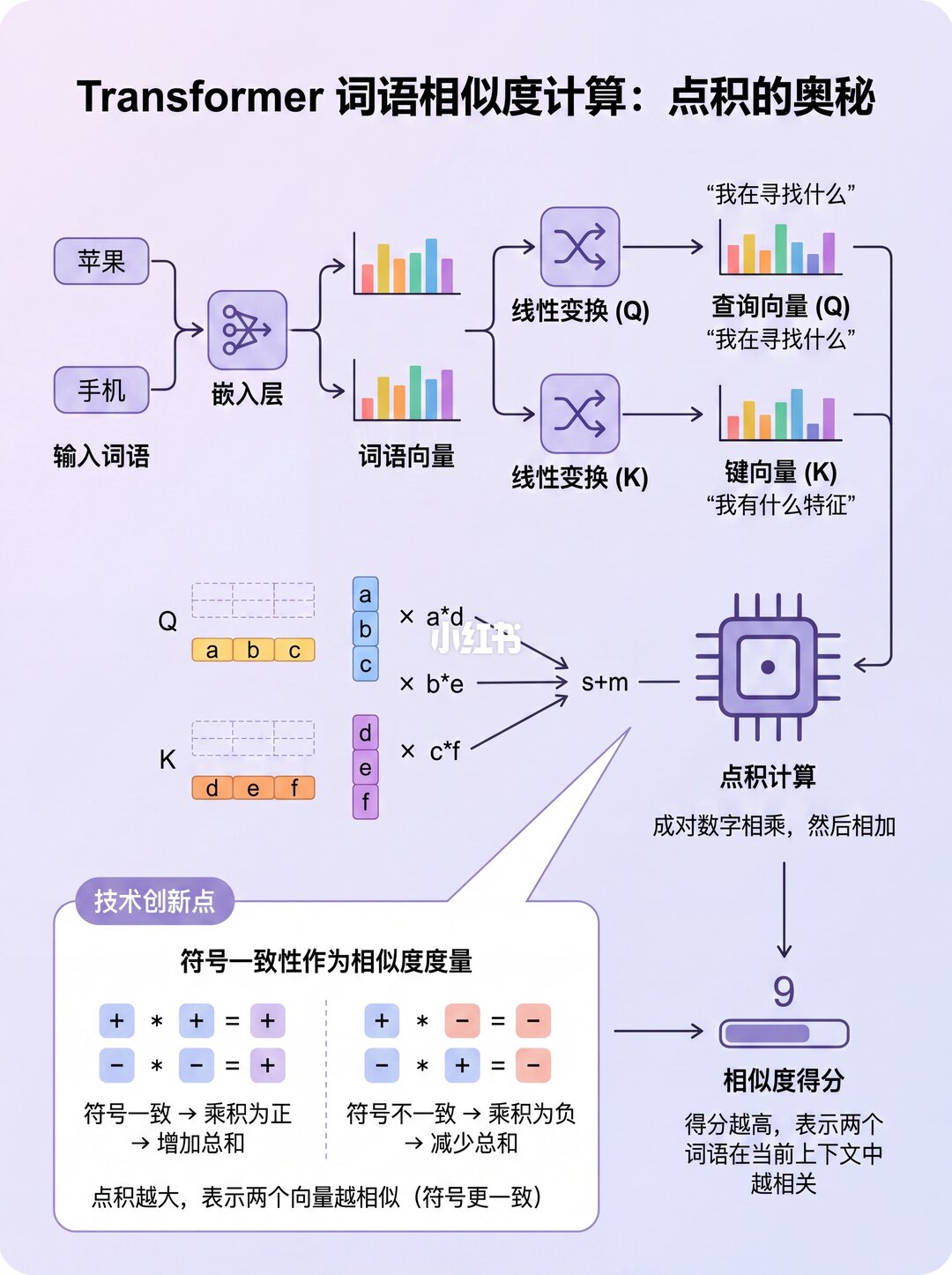
✨ 注意力分数的核心:点积
注意力计算,本质上就是矩阵乘法(点积)!
1️⃣ 先拿 Q 和 K 的转置 做点积,得到一个"因子矩阵"。这个矩阵就像一张"关系网",每个格子都是两个词的相关性。
2️⃣ 再把这个"因子矩阵"和 V矩阵 相乘,最终得到注意力分数 (Z)!
举个例子:"blue"这一行,装的就是"blue"跟句子里其他所有词的关系分数。💙
✨ 点积的魔法:词与词是如何"对齐"的?
🎯 关键点来了!点积时,如果两个向量对应数字符号一致,乘积为正,总和就大。
👉 那么:
相关的词("milk"和"drank"):向量会很对齐 → 分数高 ✅
不相关的词("milk"和"black"):向量分歧 → 分数低 ❌
所以,Transformer学会了:让相关词的向量对齐,不相关的词向量分离!这就是注意力机制的灵魂!🔥
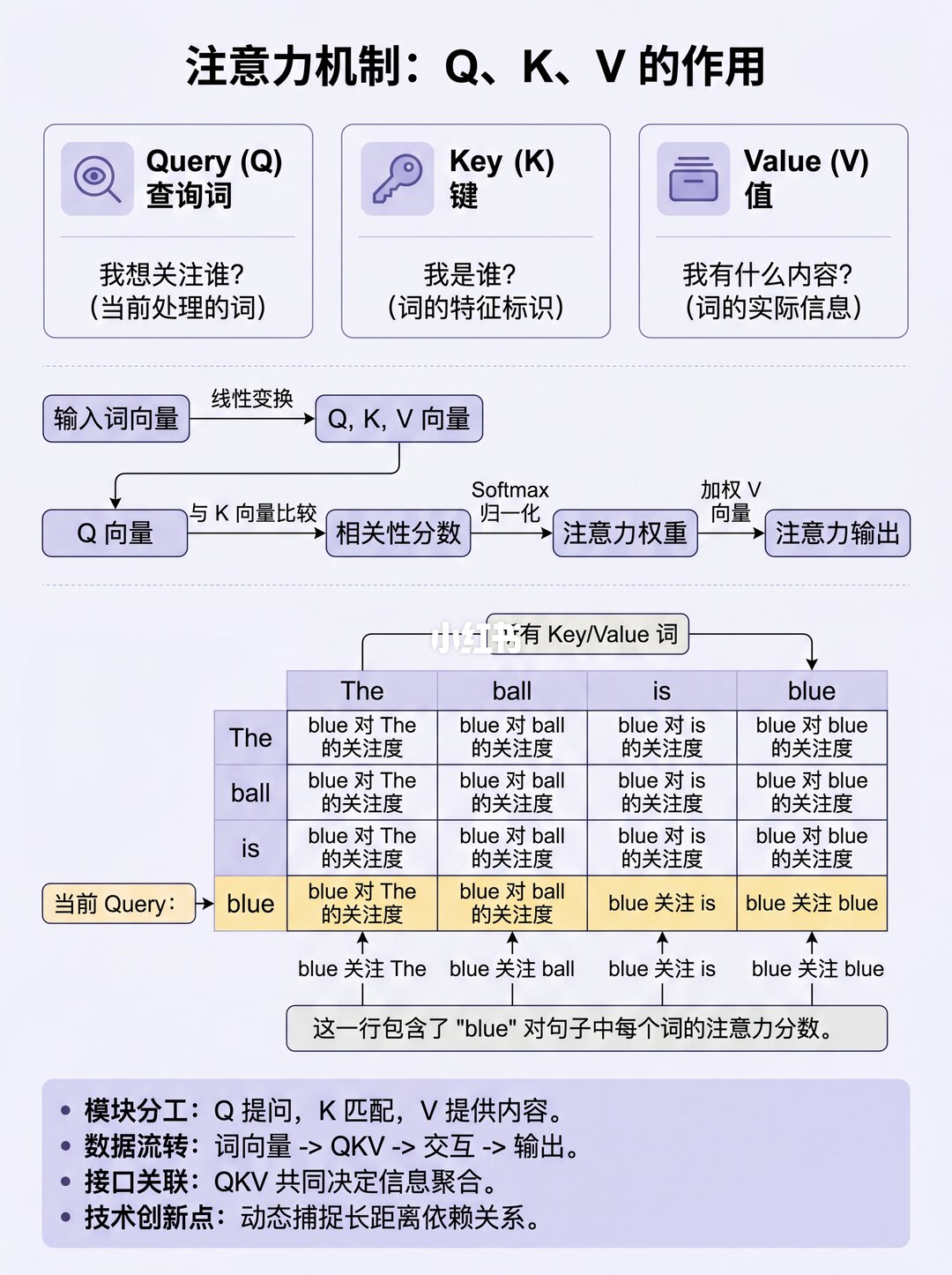
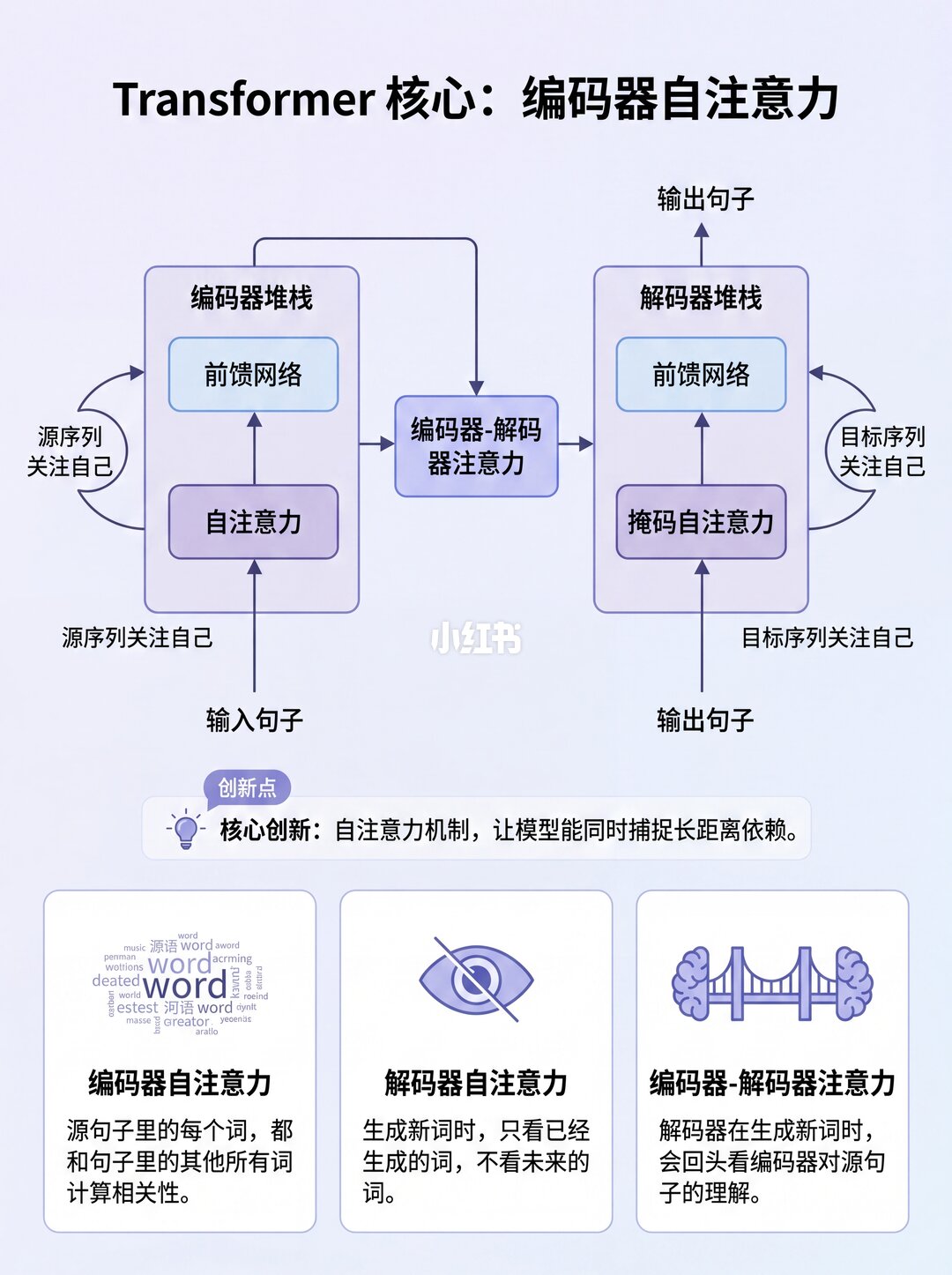
✨ 三种注意力场景,一张图看懂
1️⃣ 编码器自注意力:源句子看自己(The ball is blue 内部互相关注)
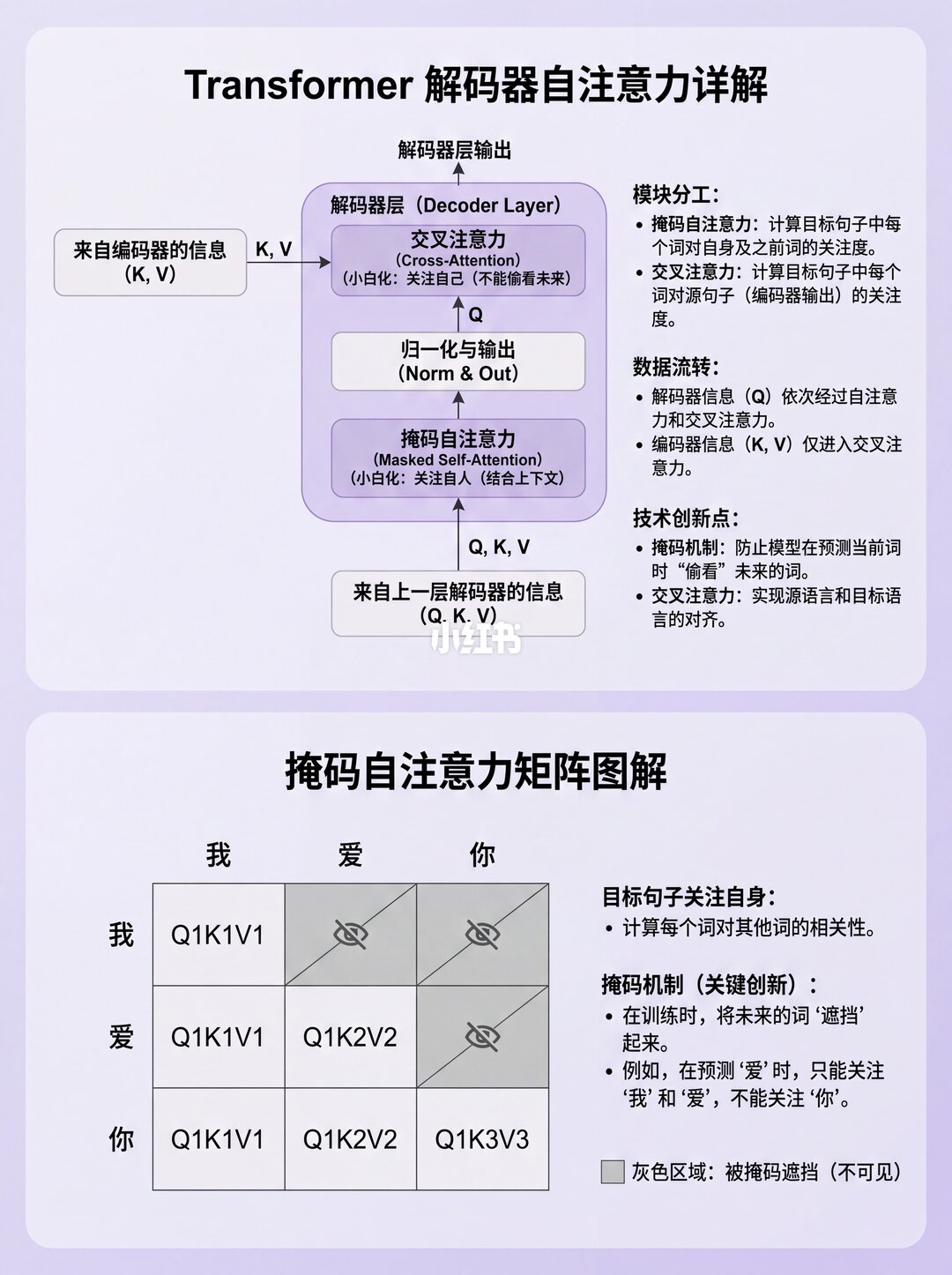
2️⃣ 解码器自注意力:目标句子看自己(La bola es azul 内部互相关注)
3️⃣ 编码器-解码器注意力:目标句子看向源句子(Query来自目标,Keyu002FValue来自源)
💡 小结一下
Transformer学着调整参数,让:
Query(我在算谁)和 Key(我在关注谁) 之间的点积,精准捕捉词与词之间的相关性。这就是它强大能力的"发动机"!🚗💨
觉得通透的,狠狠点赞收藏!💗 关注我,一起优雅地卷深度学习~✨
#transformer #注意力机制 #NLP
内容效果不满意?点此反馈