profileName: youpingfang postId: 273 postType: post categories:
- 6
在 Transformer 模型中,编码器和解码器一共有 三个注意力模块,但其中只有一个需要进行掩码处理。这是很多人学习注意力机制时容易忽略却至关重要的细节。今天我们就来深入解析这个问题的本质。
带着问题去思考
1. 为什么编码器注意力不需要掩码?
2. 为什么解码器的跨注意力模块也不需要掩码?
3. 解码器第一个注意力如果不加掩码,会导致什么问题?
4. 掩码矩阵是如何实现"只能看到之前的词"的?
一、Transformer 的诞生背景
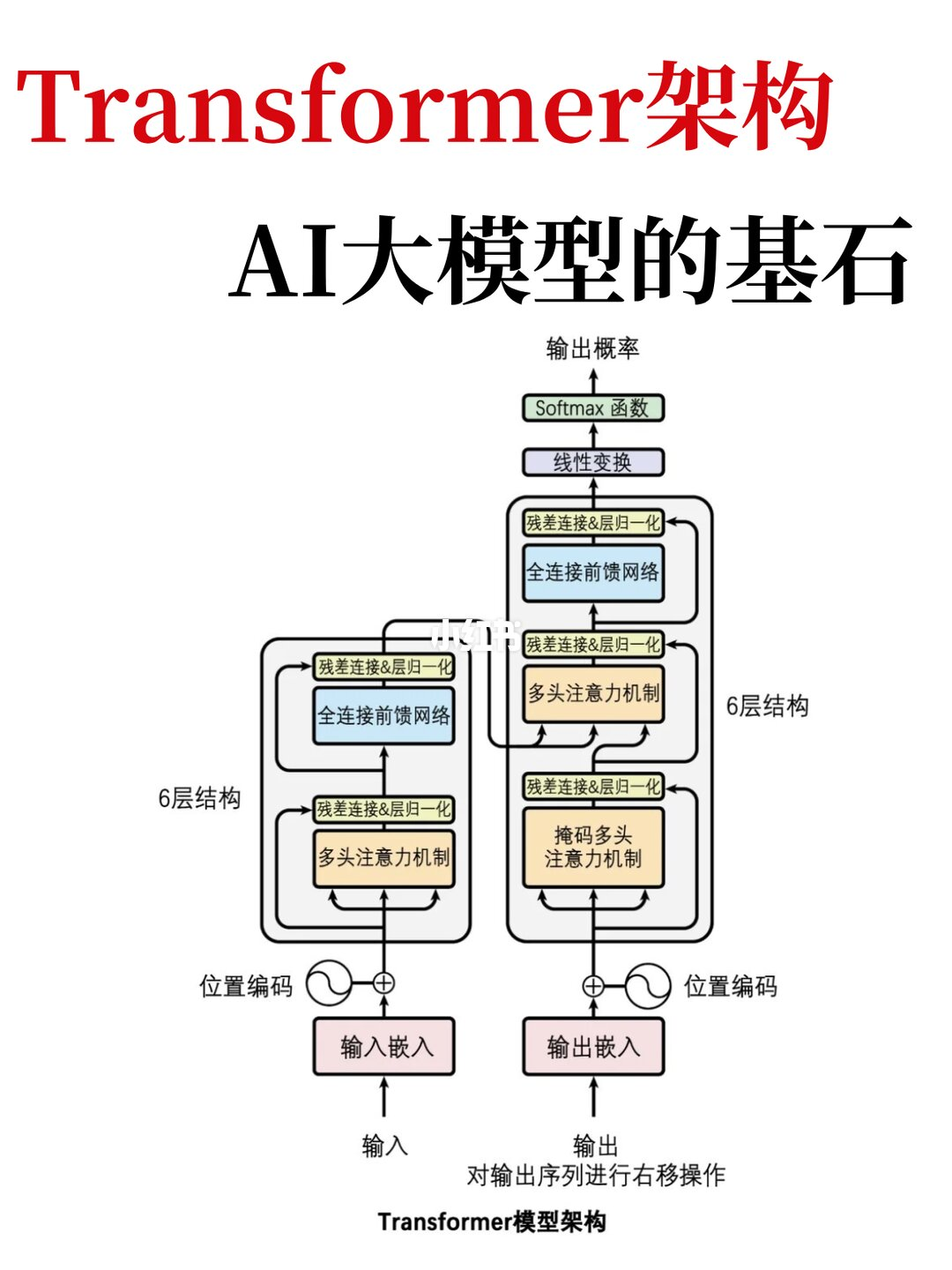 Transformer 最初被提出时,本身并非为大语言模型而设计,而是为了解决 机器翻译 任务。它使用纯注意力机制取代了 RNN,实现了并行计算,大大加快了训练速度。
Transformer 最初被提出时,本身并非为大语言模型而设计,而是为了解决 机器翻译 任务。它使用纯注意力机制取代了 RNN,实现了并行计算,大大加快了训练速度。
正因为翻译任务需要两种语言数据,Transformer 才有了左右两部分结构:
- 编码器(Encoder):输入源语言(如中文)
- 解码器(Decoder):输入目标语言(如英文)
📌 补充:编码是将信息转换为计算机可理解的格式,解码则是将这个格式再转换回目标语言。这正是"编码器"和"解码器"名称的由来。
二、三层注意力结构的分工
Transformer 的解码器中包含两个注意力模块,叠加在编码器的注意力模块之上,形成了独特的三层结构:
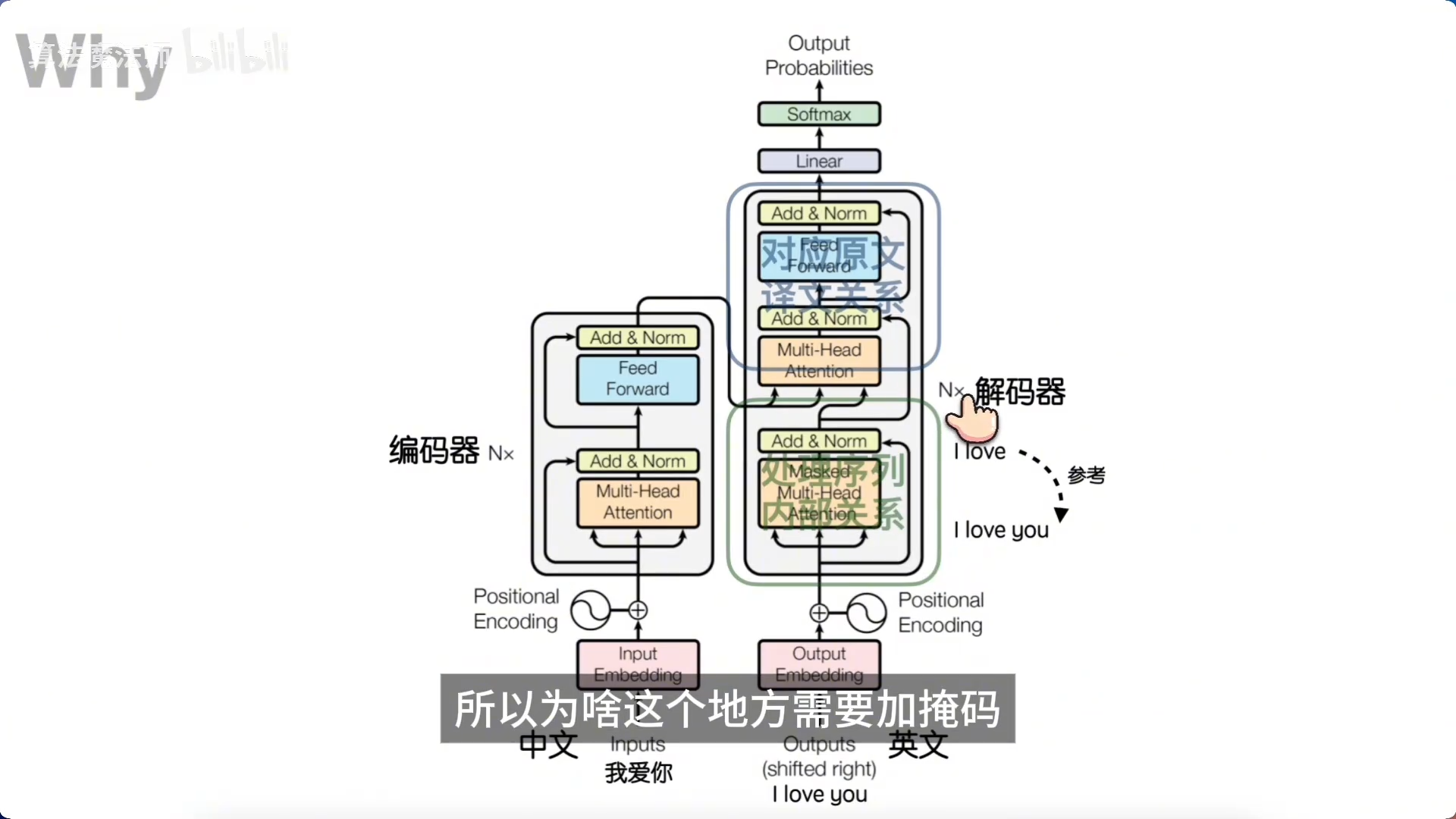
| 注意力模块 | 位置 | 作用 |
|---|---|---|
| 编码器注意力 | 编码器 | 理解源语言句子内部的关系 |
| 解码器第一个注意力 | 解码器 | 处理目标序列内部的关系 |
| 解码器第二个注意力 | 解码器 | 建立原文和译文之间的关联 |
三、为什么编码器注意力不需要掩码?
编码器的任务是理解源语言。以中文句子"我爱你"为例:
- 训练时:整个中文句子一次性输入
- 推理时:同样一次性获得完整原文
编码器需要理解整个句子的含义,然后为解码器提供参考信息,因此不需要任何掩码。
四、为什么解码器第二个注意力不需要掩码?
解码器的第二个注意力模块负责建立原文与译文之间的桥梁。它的作用是确保生成的英文是原文的准确翻译。
以翻译"我爱你"为例:
- 当解码器生成到 "love" 时
- 第二个注意力模块可以看到完整的编码器输出(我爱你)
- 这是合理的:翻译时本就应该参照整个原文
📌 补充:如果看不到完整原文,就可能出现"I love it"这样的错误翻译。
五、为什么解码器第一个注意力需要掩码?
这是本文的核心问题。
1. 自回归生成的特点
解码器的第一个注意力模块负责目标序列内部的自我关系处理,确保生成的英文符合语法和逻辑。但在训练时,必须采用自回归方式:
当前词只能看到它之前的词,不能偷看尚未生成的词。
2. 不加掩码的后果
如果不做掩码处理,会发生什么?
假设训练时输入"我爱你",正确答案输出"I love you":
- 模型在生成"love"时
- 如果能看到标准答案中的"I love you"
- 它会直接"照抄"后面的内容
- 交叉熵误差永远为 0
- 模型权重无法更新
- 训练失效
3. 类比学习
这和我们人类学习是一样的道理:
- ❌ 一开始就抄答案 → 看似每次满分,但遇到新题就傻眼
- ✅ 靠自己解题 → 初期错误多,但总结经验后能力不断提升
📌 补充:掩码机制的本质是强迫模型独立思考,从而获得真正的泛化能力,而非机械记忆训练数据。
六、掩码的具体实现
理解了为什么要掩码,具体如何实现呢?
1. 注意力矩阵
在计算注意力时,会输出一个权重矩阵,表示句子中每个词与其他词的相似度关系。
2. 掩码操作
掩码的实现非常直接:
3. 计算过程
经过 Softmax 激活后: - 上三角区域的负数值全部变为 0 - 每个词只能"看到"自己和之前的词
以"I love you"为例: - 第1个词"I" → 只能看到自己 - 第2个词"love" → 只能看到"I" - 第3个词"you" → 只能看到"I love"
七、总结
| 注意力模块 | 是否需要掩码 | 原因 |
|---|---|---|
| 编码器注意力 | ❌ 不需要 | 源语言一次性全量输入,不存在"偷看"问题 |
| 解码器第二个注意力 | ❌ 不需要 | 翻译需要参照完整原文,这是正确的行为 |
| 解码器第一个注意力 | ✅ 需要 | 防止模型偷看标准答案,确保自回归训练有效 |
💡 一句话理解:掩码机制是 Transformer 能够"学会"翻译逻辑而非"背诵"训练数据的核心保障。
答案
1. 因为编码器需要提供完整的背景信息 编码器就像翻译者,翻译时必须看到完整的源语言文本才能准确理解其含义。训练和推理时,源语言都是一次性全量输入,不存在"提前偷看答案"的问题。
2. 因为跨注意力负责实际的翻译工作 跨注意力需要看到两个信息:①编码器输出的完整原文(背景信息)②解码器第一个注意力输出的已翻译文本(决定下一个词)。翻译需要参照这些信息,这是正确的行为。
3. 会导致模型"作弊",无法学会真正的翻译逻辑 如果能看到标准答案,模型会直接照抄,交叉熵损失为0,权重无法更新。这样训练出的模型要么是"傻子",要么只会复述训练数据中的句子,无法泛化到新的翻译任务。
4. 使用下三角矩阵,下三角为0,上三角为负无穷 经过 Softmax 激活后,负无穷的位置变为0,确保每个词只能"看到"自己和之前的词。具体实现:下三角和对角线位置设为0(可看),上三角位置设为负无穷(不可看)。