author: 鸟哥 | 蓝鸟会🕊️ source: X url: https://twitter.com/nftcps/status/2052564688404353231?s=12&t=1Ejh2Wy1m_e4R74MeX_shA saved: 2026-05-08 15:29:00 tags: - 笔记同步助手
id: c997569e-00b7-4993-b039-6f4071b30a6a
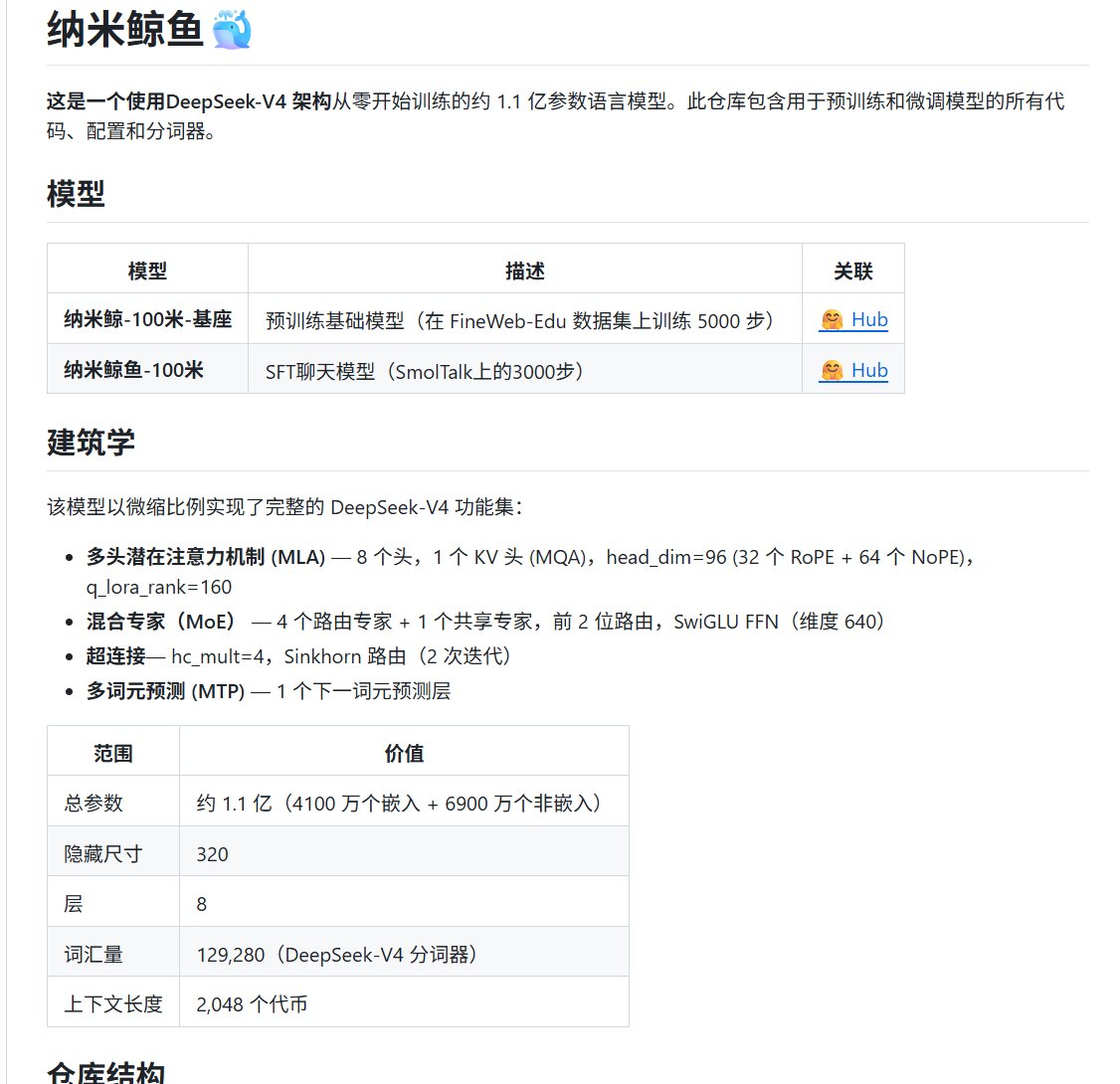
卧槽,HuggingFace又搞了个狠活!DeepSeek-V4架构直接搬到110M小模型上,这下连菜狗都能玩转MLA、MoE那些高大上的新特性了。
🔥 核心亮点拆解:
1️⃣ 架构全家桶:MLA(8头+1KV头)+ MoE(4路由+1共享专家)+ Hyper-Connections(Sinkhorn路由)+ 多token预测,跟DeepSeek-V4一模一样
2️⃣ 训练数据:先用FineWeb-Edu预训练5000步(2.6B tokens,loss压到5.3),再用SmolTalk做SFT 3000步(准确率从36.2%飙到48.5%)
3️⃣ 踩坑警告:bf16下Hyper-Connections直接爆NaN,必须换fp32;还有个雷——129K词表贼大,光嵌入就吞了37%参数
这波操作明摆着是给打工人练手的,想研究大模型新架构又不想烧显卡的,直接开干就完事。
🔗 https://github.com/huggingface/nanowhale
评论
真奈(Mana) @nice11018
@NFTCPS 小模型也能玩转大架构,这波开源让技术门槛又低了。
内容效果不满意?点此反馈