Flash Attention 原理
Flash Attention 是目前大模型训练与推理中的关键技术。它通过优化 GPU 底层算子,在不损失模型精度的情况下,既提升计算速度,又减少显存占用。要理解 Flash Attention,需掌握两点:传统分块 Self-Attention 的计算过程;为何以及如何对 Softmax 进行分块计算
GPU 工作原理
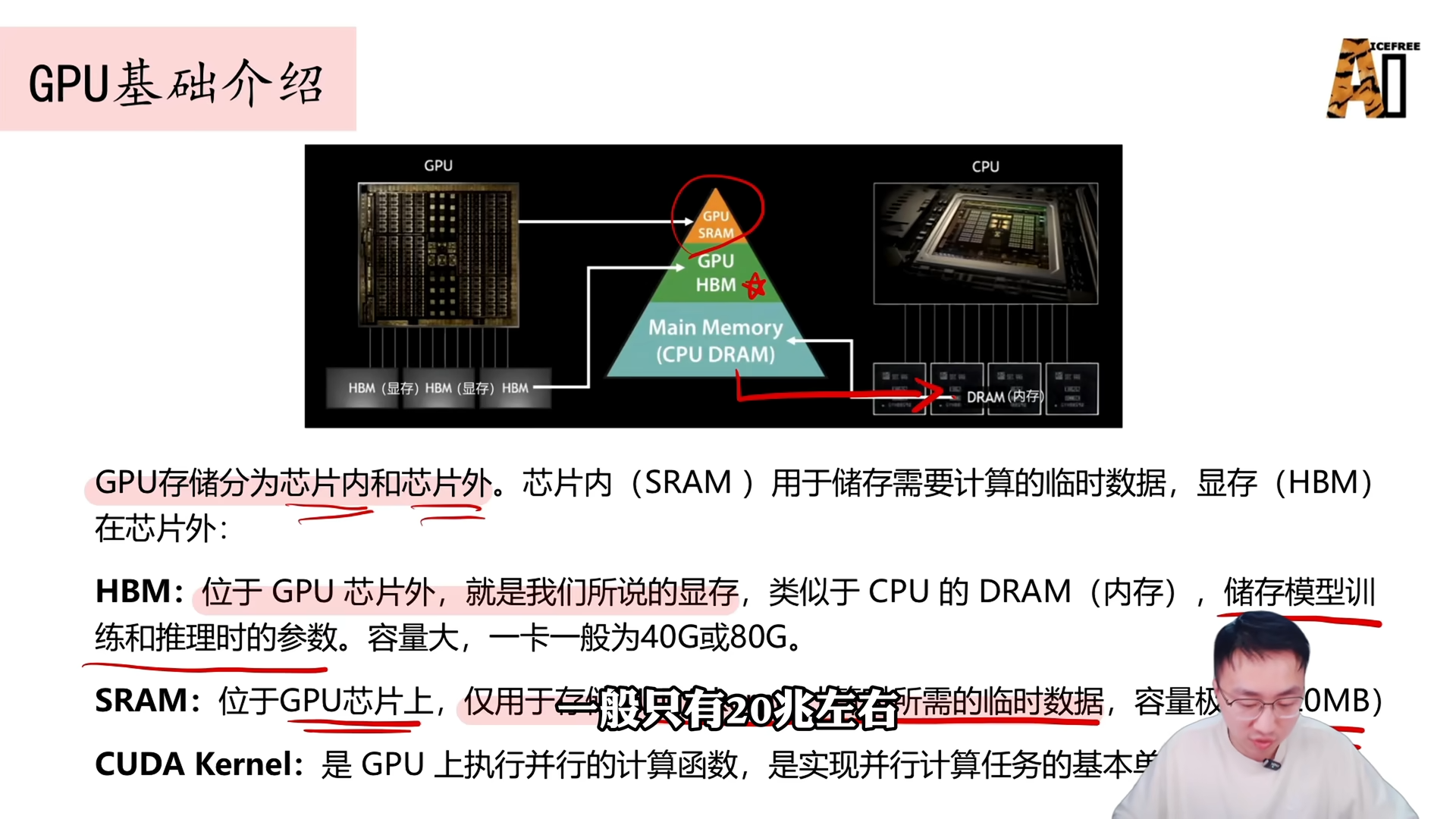
GPU 的存储分为芯片内和芯片外(即 HBM 显存)。芯片内(SRAM)用于存储计算时的临时数据,容量小(A100 约 20~40MB),但带宽高。显存(HBM)位于芯片外,容量大,用于存储模型参数及中间结果。
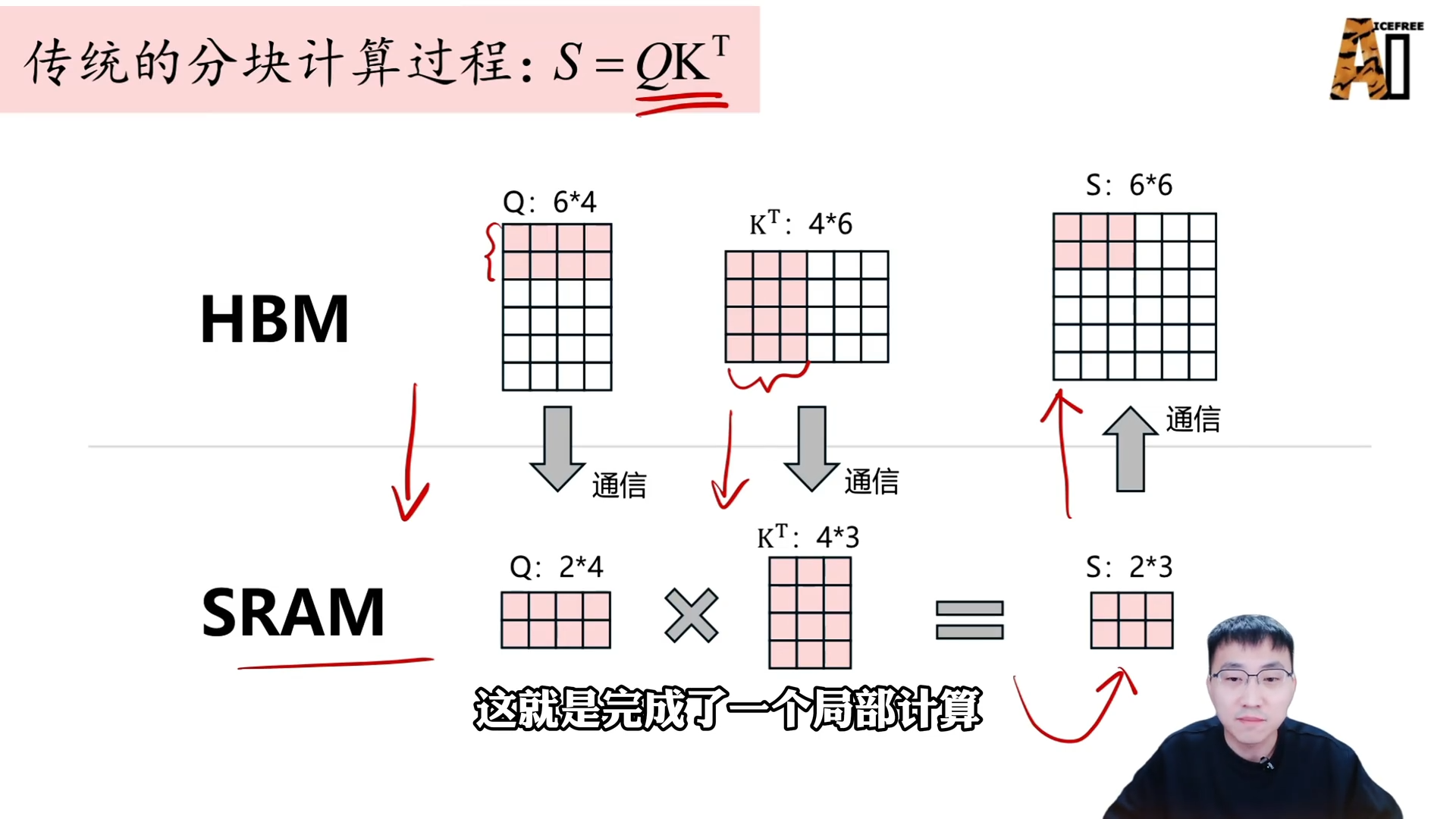
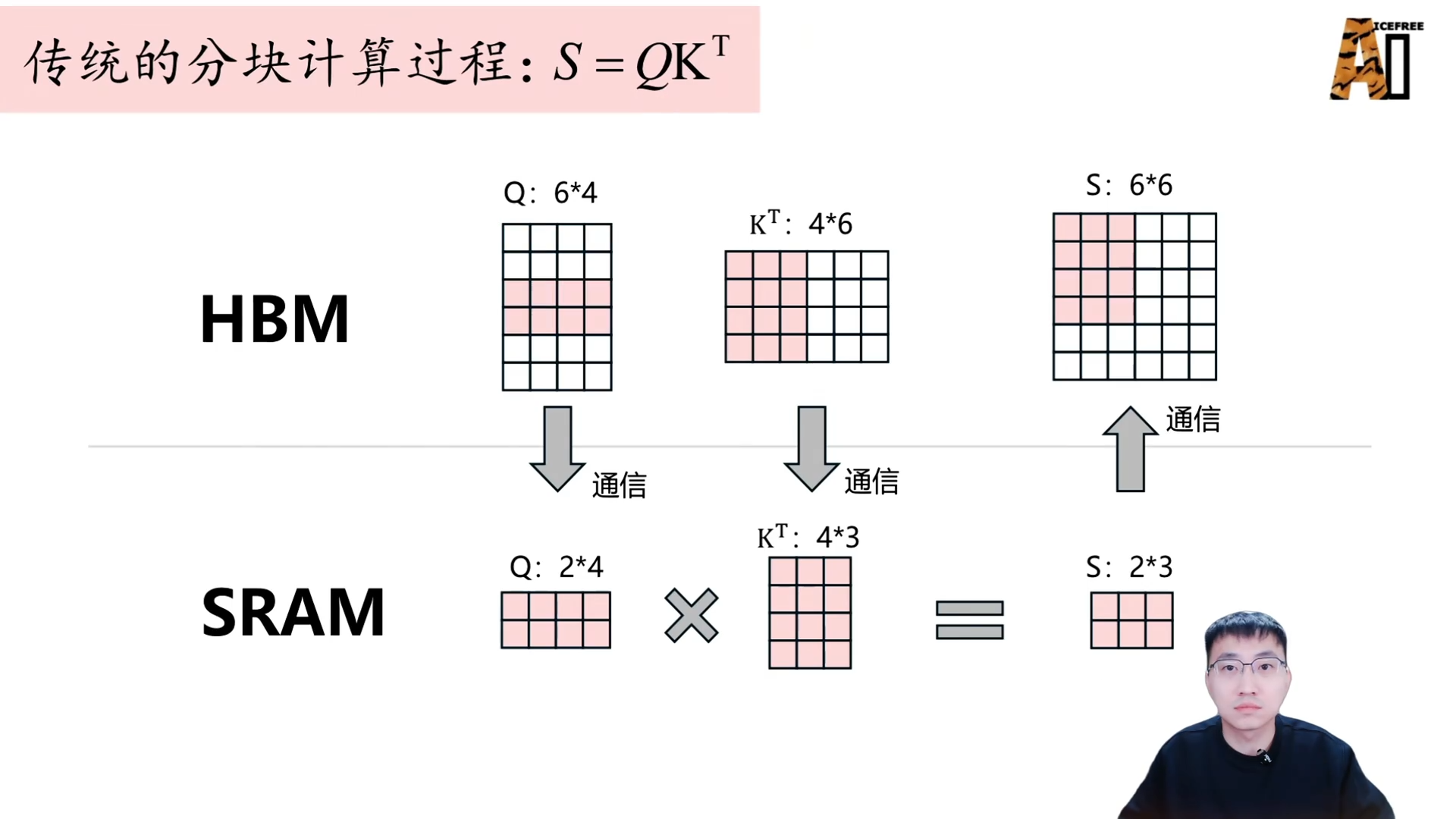
传统分块注意力计算
由于自注意力中的 QKV 矩阵计算量巨大,尤其面对长序列时,SRAM 无法容纳,因此需要分块计算。
- 分块:将 Q、K、V 矩阵分割为若干小块。
- 加载计算:将 Q 的若干行与 K 的若干列加载到 SRAM,计算局部注意力矩阵。
- 结果写回:将局部结果写回 HBM。
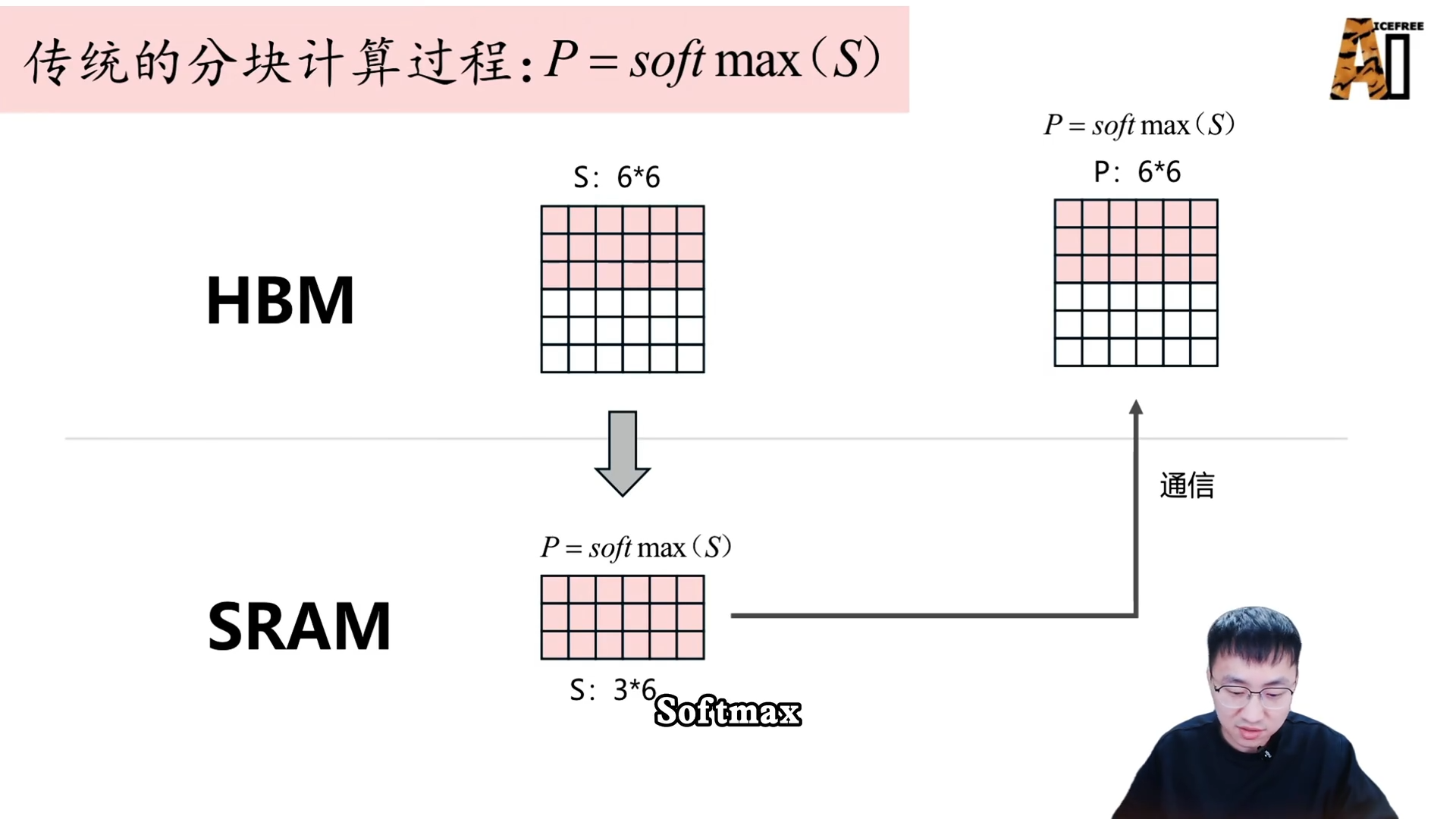
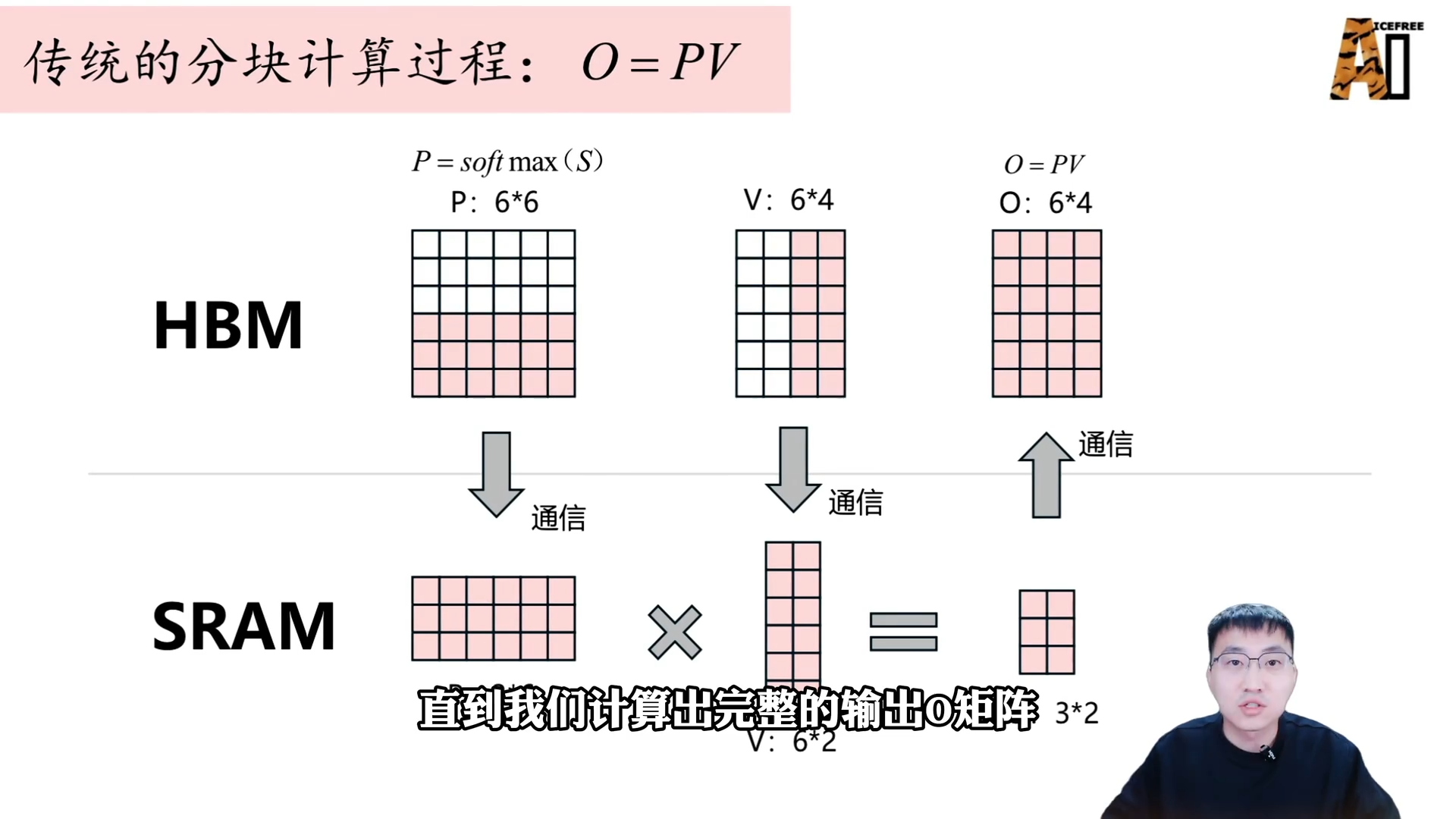
- 循环:重复上述步骤,直到计算完所有分块,再同样分块计算 Softmax 和与 V 的矩阵相乘,得到最终的输出矩阵 O。
此传统方法需要
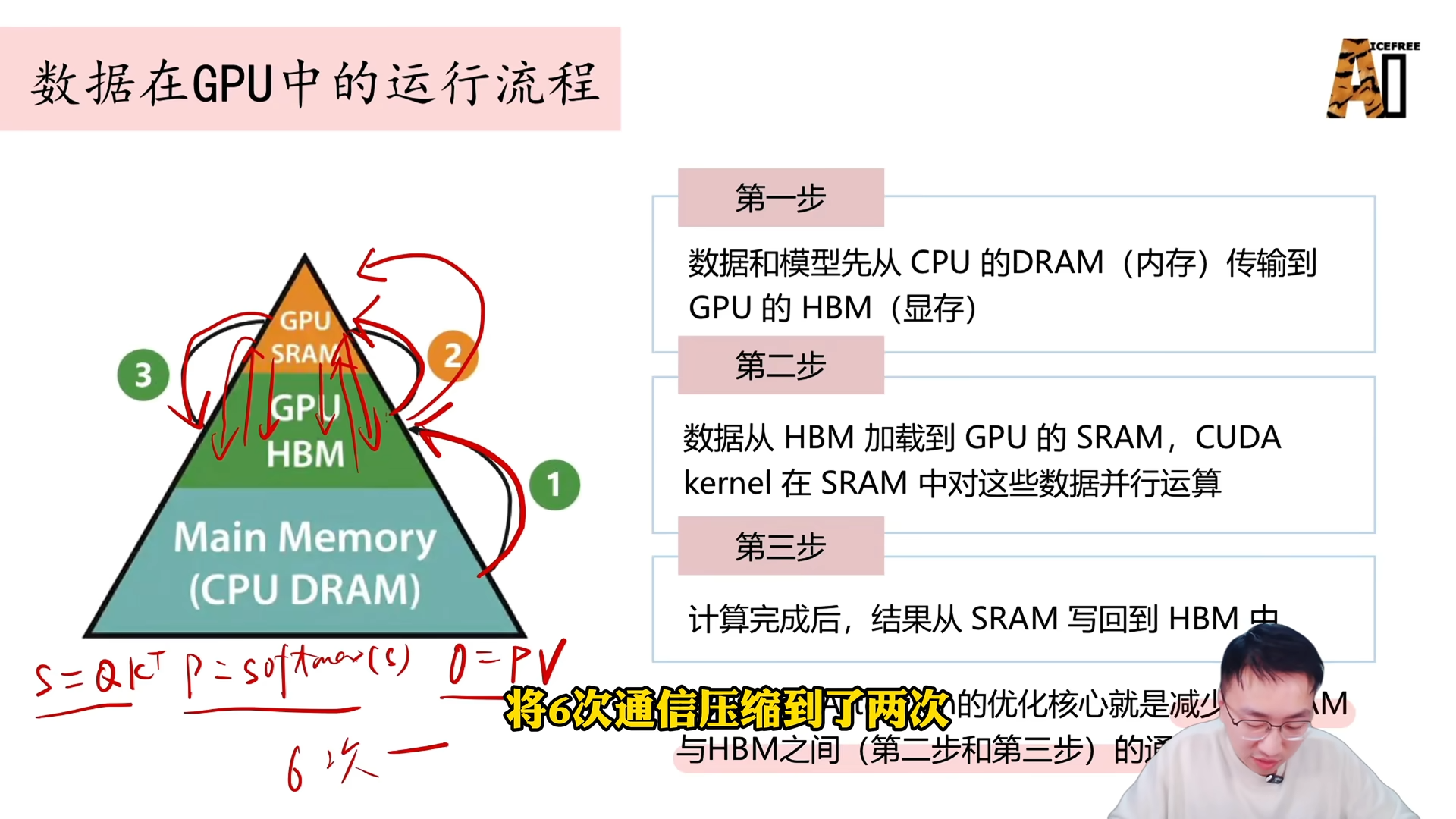 6 次 HBM 与 SRAM 之间的通信(3 次写入、3 次读出)。Flash Attention 的核心贡献之一是将通信次数优化为 2 次(一次写入、一次读出)。
6 次 HBM 与 SRAM 之间的通信(3 次写入、3 次读出)。Flash Attention 的核心贡献之一是将通信次数优化为 2 次(一次写入、一次读出)。
Softmax 的分块计算
Softmax 在分块场景下的计算难点在于:分块时,每一小块只有局部统计量。为了解决此问题,需要进行动态合并。
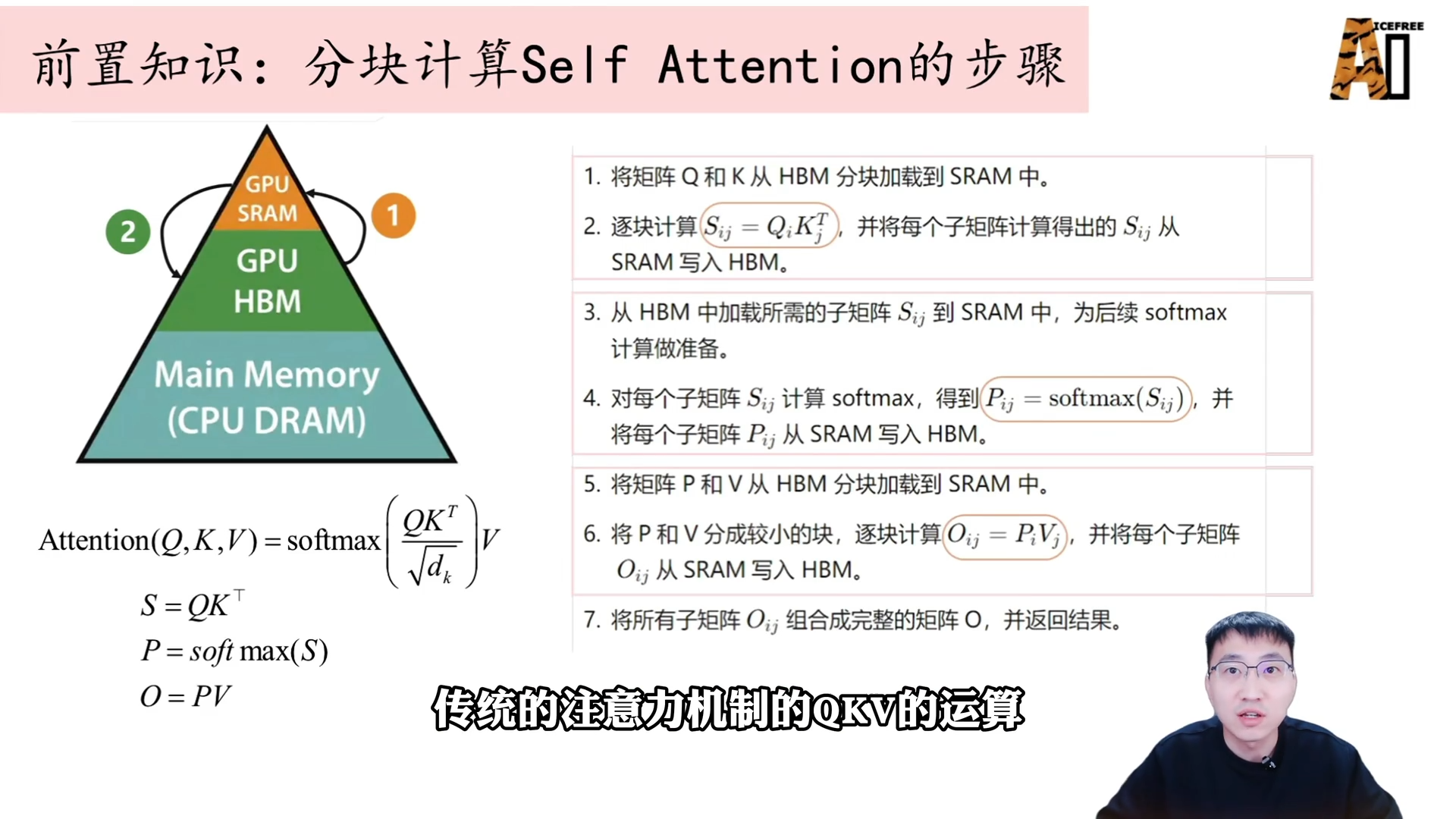
分块 Softmax 步骤(以向量 [1,2,3,4] 分为两块为例):






- 计算局部最大值:第一块最大值为 2,第二块为 4。
- 计算局部分子:用每个元素减去本块的最大值,求指数。第一块分子为 e^{1-2} + e^{2-2} = e^{-1} + 1;第二块分子为 e^{3-4} + e^{4-4} = e^{-1} + 1。
- 计算局部分母:对分子求和。
- 合并最大值:全局最大值为 4。
- 更新全局分母:对于第一块元素,其局部最大值是 2,需减去全局最大值,因此需额外乘以一个缩放系数 e^{2-4}。(原文此处描述有误,实际并非直接减去差值,而是利用指数性质进行变换调整,保证最终 Softmax 结果准确。)
以上是 Flash Attention 对 Softmax 的在线(Online)计算优化。通过维护并迭代更新全局最大值和全局分母(归一化因子),可以在分块完成后得到与全局 Softmax 完全一致的结果。
复杂度分析

- 原始 Softmax:需三次遍历(找 max -> 分子分母 -> 最终值),复杂度 O(n^3)(原文此表述不准确,正确应为:对序列长度 n 的向量做一次 Softmax 是 O(n),但注意力机制中的 QK^T 计算是 O(n^2)。)
- 在线 Softmax:将找最大值与计算分子分母合并为一步遍历,复杂度降低(正确表述应为:通过分块计算,将注意力矩阵的显存占用从 O(n^2) 降低为 O(n),同时利用分块策略减少 IO 开销)。
总结:Flash Attention 的两大支柱
Flash Attention 的核心是减少 HBM 与 SRAM 之间的通信。论文中具体包含两部分:
- Tiling(分块):将大矩阵分块,逐块计算并增量更新中间变量,避免一次性计算完整注意力矩阵。
- Recomputation(重计算):在反向传播时,仅保留部分中间统计量(如 Softmax 的局部最大值与归一化因子),需要时重新计算部分注意力权重,以节省显存。这类似于梯度检查点技术。(原文将 Recompution 解释为“基于跳脸技巧”,此表述不准确,此处已修正。)
凭借上述优化,Flash Attention 可将训练速度提升 2~4 倍,显存占用从平方增长降低为线性增长。
如果大家需要资料,可以在同名公众号 AI有温度 后台回复 flash 获取资料。
面试题与答案
Q1:Flash Attention 的基本原理是什么?
A1:Flash Attention 的核心思想是将注意力计算从 GPU 的 HBM(高带宽内存)转移到芯片内的 SRAM 中执行,以利用 SRAM 的高带宽(约 HBM 的 20 倍)。由于 SRAM 容量极小,算法采用分块加载 Q、K、V 并逐块计算,再通过在线 Softmax 等数学技巧保证分块结果与全局计算结果一致。这种方法大幅减少了 HBM 的读写次数,实现了在精度无损的前提下,同时提升速度并降低显存占用。
Q2:传统 Softmax 在分块计算时存在什么困难?Flash Attention 如何解决?
A2:传统 Softmax 需要获取整行数据才能确定全局最大值与全局指数和,分块后每小块只有局部统计量。Flash Attention 采用在线 Softmax 技巧,每计算一个分块时,算法会记录并动态合并已计算数据的统计量,利用指数运算的数学性质,在逐块计算过程中同步更新全局归一化因子,保证最终结果与全局 Softmax 完全一致。
Q3:Flash Attention 如何节省显存?
A3:Flash Attention 通过分块计算,无需存储完整的 N×N 注意力矩阵(中间结果 S 和 P),显存占用从 O(n^2) 降为 O(n)。此外,在反向传播中,它不保存所有的注意力权重,只保留少数中间统计量,在需要时通过重计算方式恢复权重,进一步节省显存。这种策略使得模型可以支持更长的上下文窗口。
Q4:Flash Attention 通过什么方式实现了计算速度的提升?
A4:一是通过分块策略,将计算主要安排在高速 SRAM 中进行,显著减少了与慢速 HBM 的读写交互。二是优化了 IO 通信次数,将传统分块方法所需的 6 次通信减少为 2 次,大幅降低了 IO 开销。三是通过将 Softmax 的局部计算与全局合并步骤巧妙整合,避免了对完整矩阵的多次遍历。