source: 小红书 url: https://www.xiaohongshu.com/discovery/item/6a23fa5c0000000021009338?app_platform=ios&app_version=9.25&share_from_user_hidden=true&xsec_source=app_share&type=normal&xsec_token=CBsLOzgCVtJaacEj_yHAaB9FSUfmI6GLkuCfBXsM8zUBE=&author_share=1&xhsshare=WeixinSession&shareRedId=ODY7Nzs8ND02NzUyOTgwNjY0OTc5Sz85&apptime=1780750072&share_id=c11b4ef59b774b708d605ed20c13a16b saved: 2026-06-06 20:48:45
id: 79c8df21-edeb-4ed1-b787-bb7c013e7c93
作者: Vincent | AIGC
发布/编辑时间: 2026年06月06日 10:45
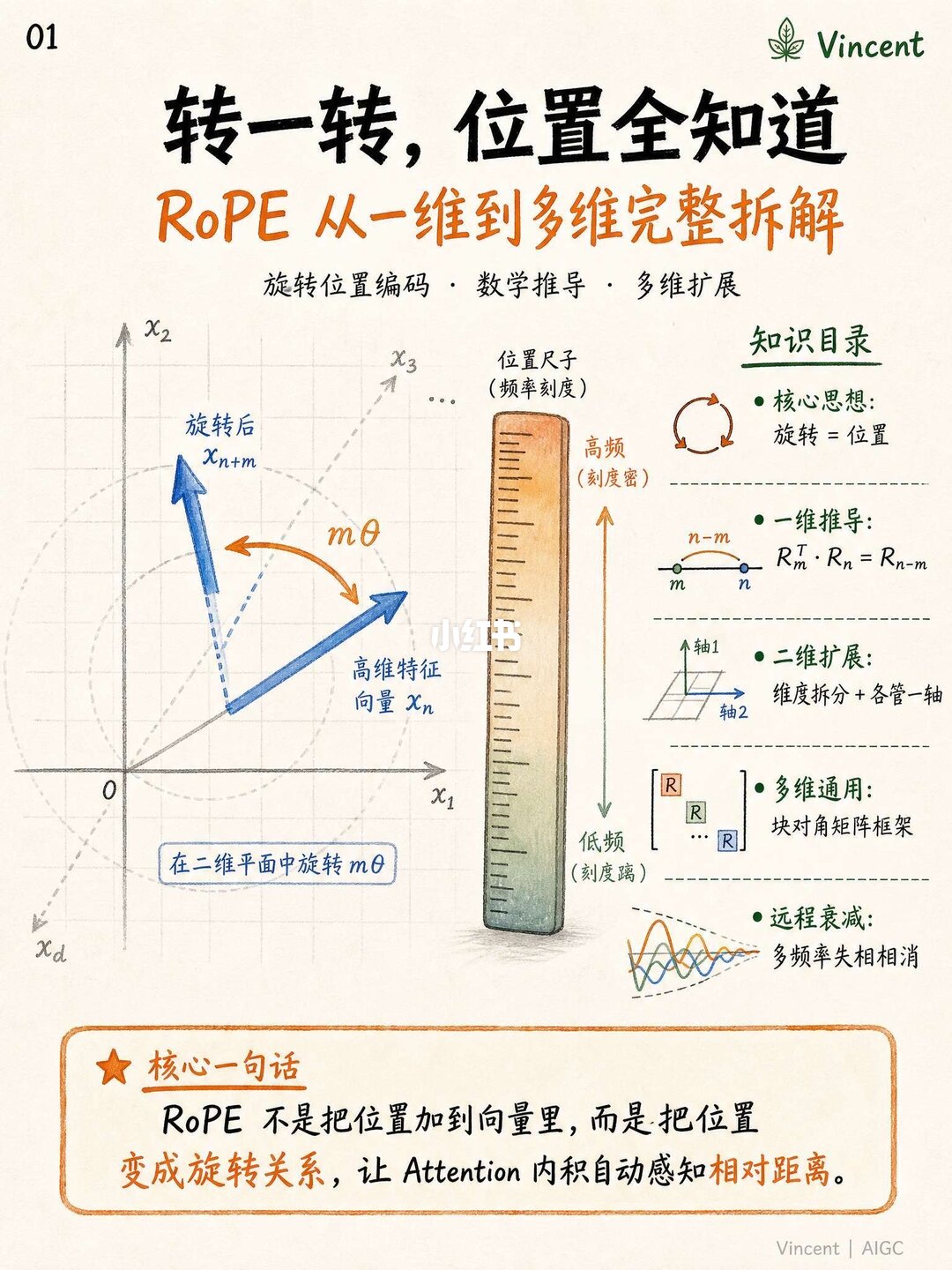
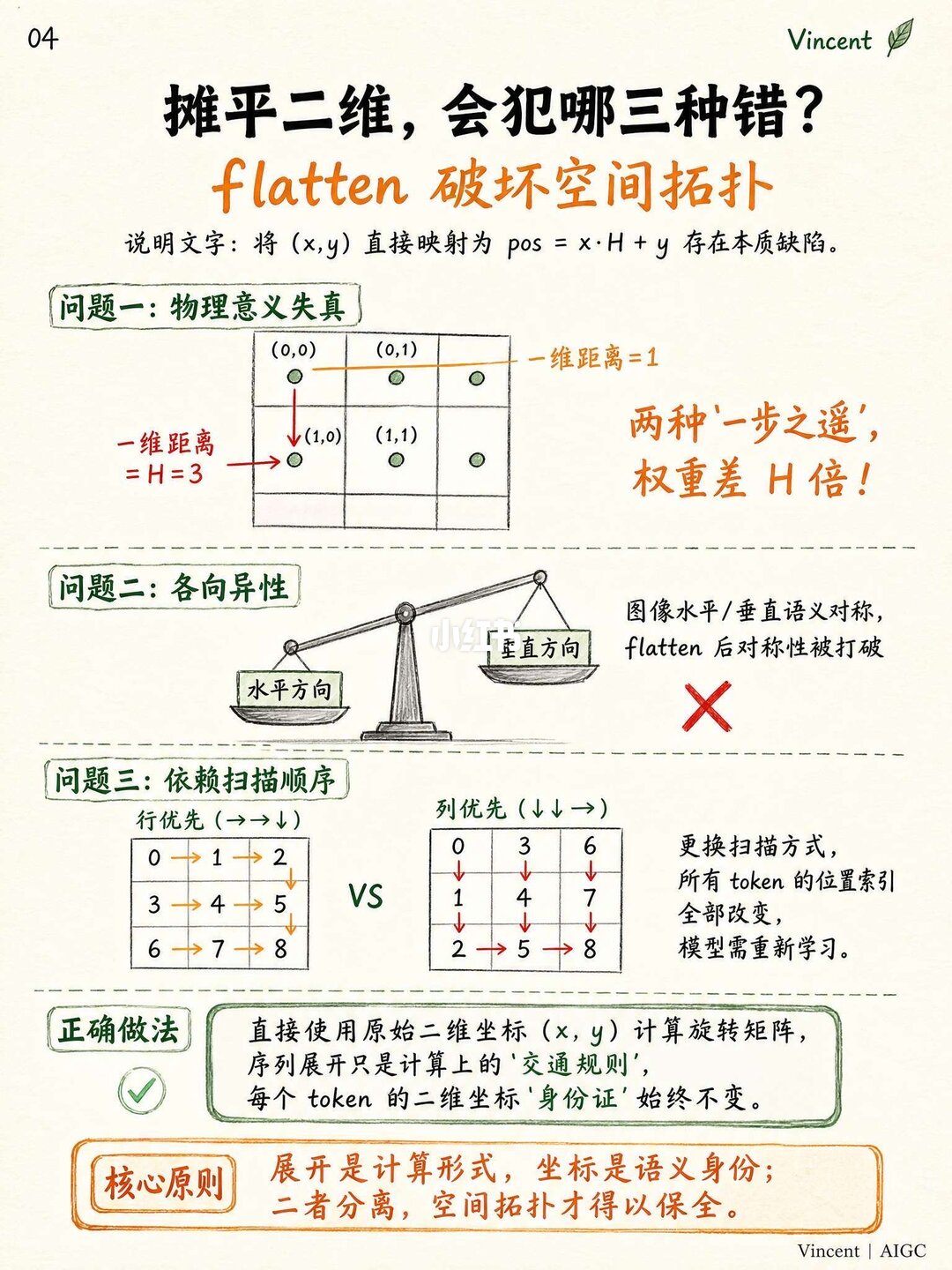
最近看多模态和DiT(比如各种生图、视频生成的架构),发现大家都在聊多维RoPE。以前做文本的1D RoPE挺直观的,但图像是2D的,很多人最容易犯的直觉错误就是:直接把图像强行拉平(Flatten),然后直接套1D位置编码。
其实这中间有个大坑。你想想,在图上本来上下相邻的两个像素,一旦强行拉平,它们在序列里的距离直接被拉开了几百倍。原本“一步之遥”的关系,直接变成了“最遥远的距离”,图像的空间结构完全被搞崩溃了。
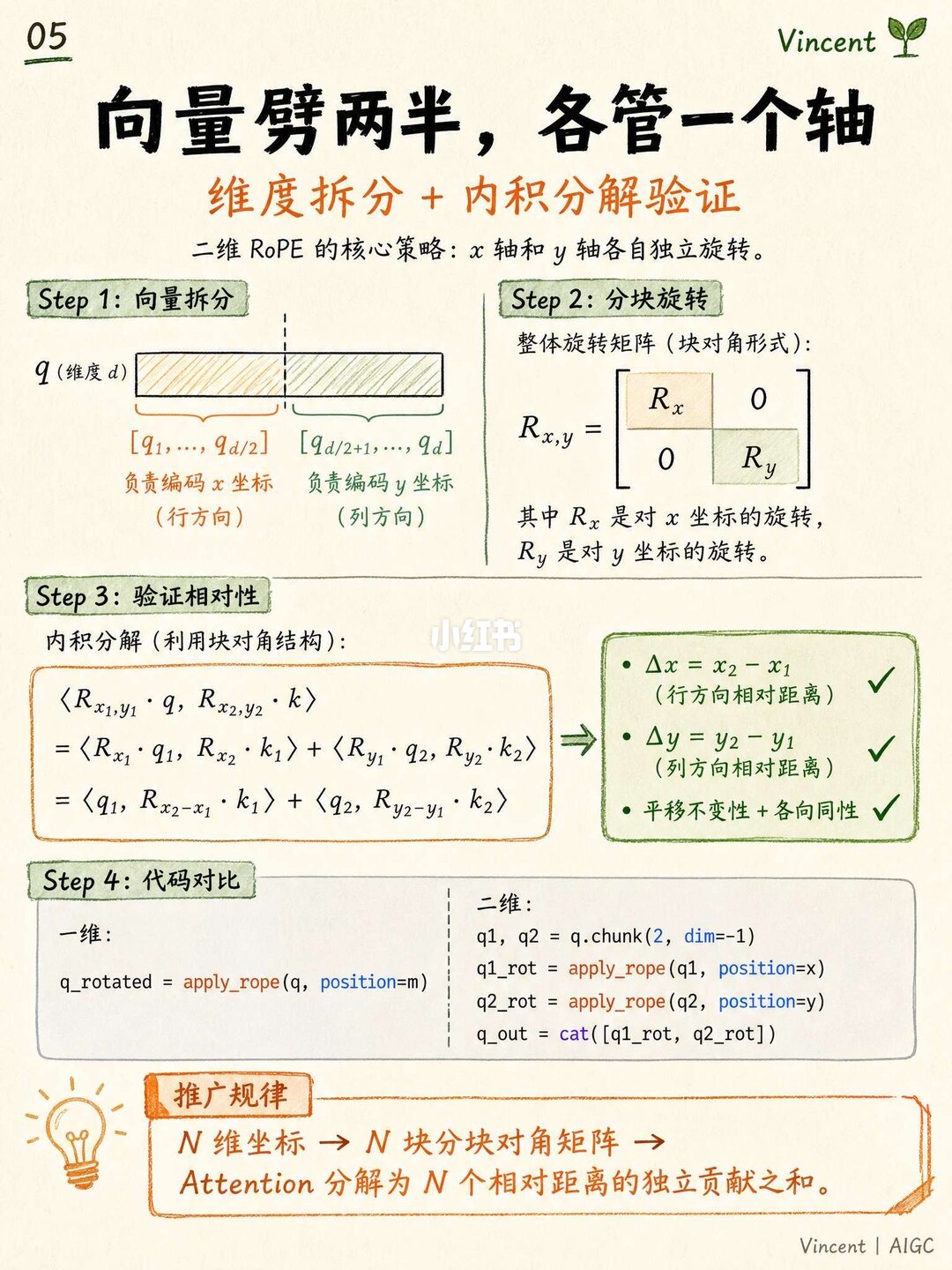
那DiT里是怎么优雅解决的?其实就是维度拆分。
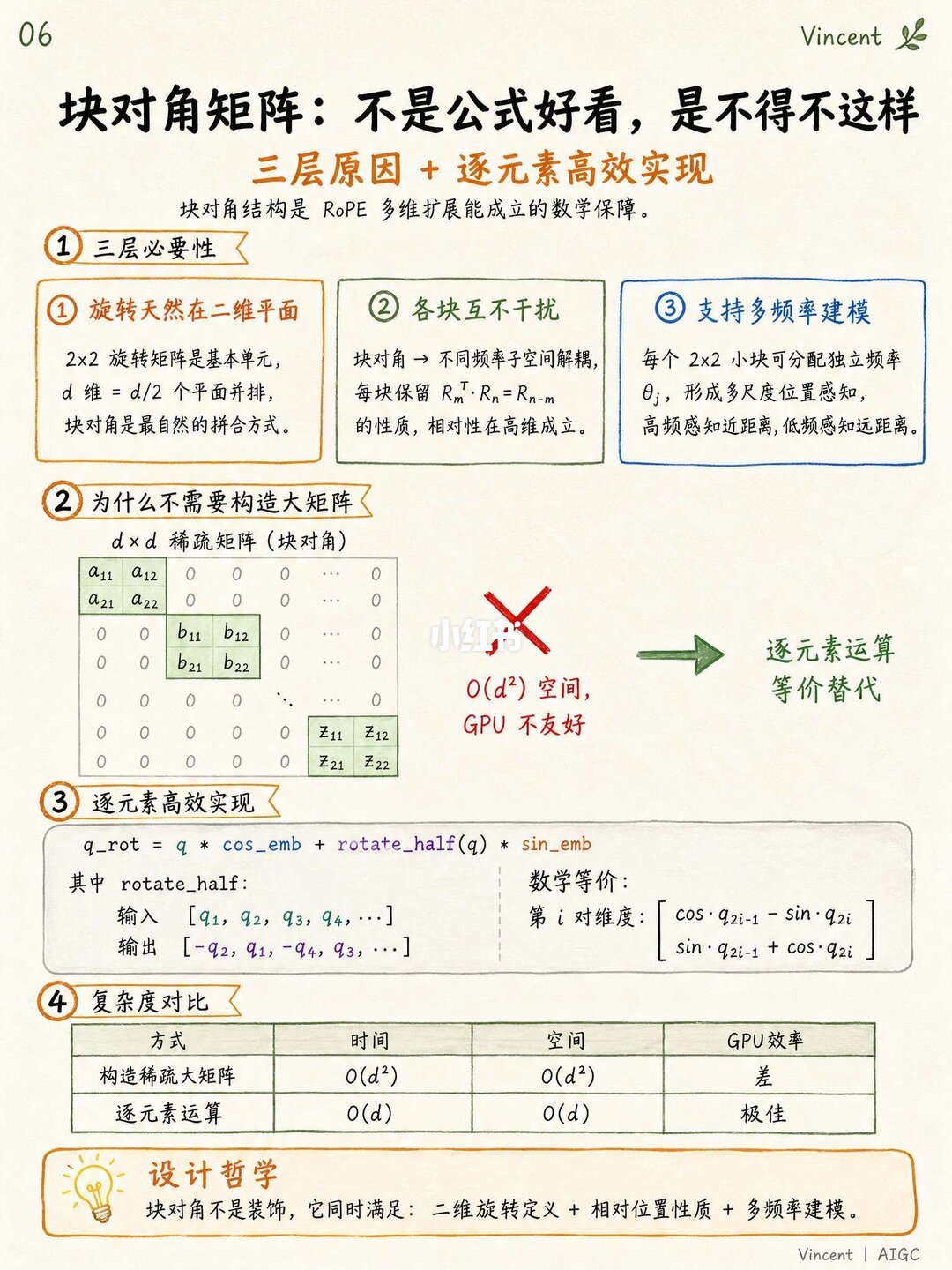
说白了就是把Embedding维度一分为二,各玩各的:前半部分负责水平方向的旋转,后半部分负责垂直方向。当Q和K做点积乘起来的时候,由于分块对角的数学特性,横向相对距离和纵向相对距离会自动合并出来,完全不会互相干扰,2D拓扑结构保全得极好。
这样做还有一个巨大的工程好处:如果处理纯文本,直接把Y轴坐标全设成1,它就自动退化回最普通的1D RoPE了。不需要大费周章去重新改大模型的底子,也不需要写自定义的GPU算子,直接用原生PyTorch切分一下拼起来就能跑,把向后兼容和省算力玩明白了。
手绘图最后还提到了一个很有意思的物理学隐喻:为什么RoPE天生就有“近强远弱”的局部偏差?
因为RoPE有很多个不同的旋转频率。离得近的时候波段还能对齐,离得远了,不同频率的波段会直接“相位干涉相消”,注意力权重呈指数级往下降。这跟声波、电磁波在介质里的物理衰减简直一模一样,数学和物理的对称美感直接拉满。
看完这组笔记确实对多维位置编码“祛魅”了,其实底层的设计思路非常直观,就是用最简单的切分解决了高维空间的投影难题。
#ROPE #DiT #位置编码 #多模态 #大模型 #算法日常



内容效果不满意?点此反馈