总结:RAG 知识库文本分块详解
本文系统性地介绍了 RAG(检索增强生成)系统中知识库文本分块(Chunking)的完整流程,包括分块前的文档清洗、核心分块方法及其优缺点、以及元数据管理,旨在为后续的向量化检索奠定高质量的数据基础。
一、 为什么需要文本分块?
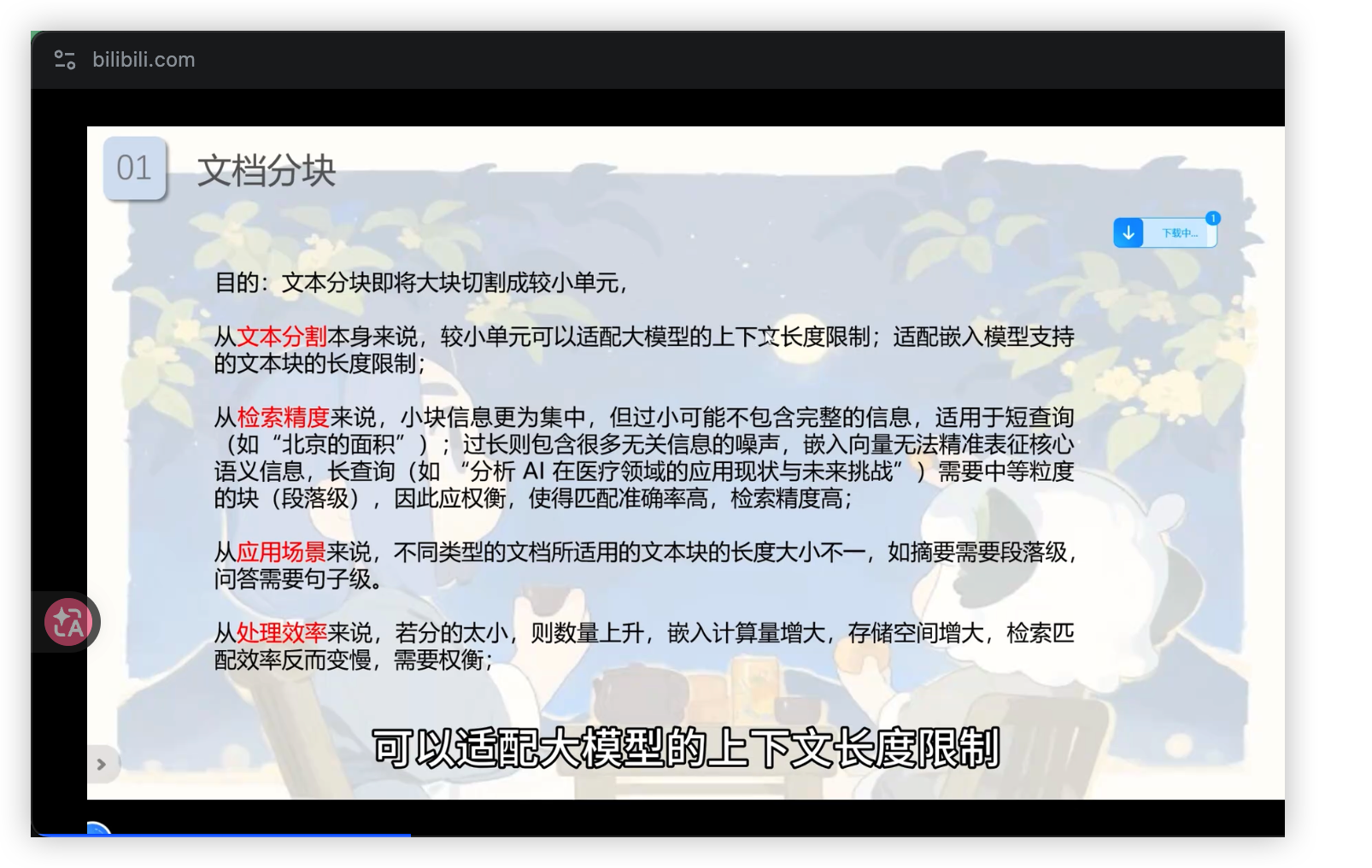
分块是 RAG 检索质量的关键前置步骤,其必要性源于三点:
- 突破上下文窗口限制:大模型能处理的 Token 数有限,无法一次性接收整个长文档。
- 提升检索精度:将文档切分为语义小块,便于检索时仅返回与用户 Query 最相关的若干个块(如 Top 3、Top 5),既保证信息相关性,又控制 Token 消耗。
- 平衡信息粒度:块太大则无关噪声多,检索准确率下降;块太小则可能割裂完整语义,丢失关键信息。因此,分块策略需要在“完整性”和“精确性”之间找到平衡点。
二、 分块前的文本清洗
文本提取后,需先进行清洗以去除噪声、规范化格式,提升后续分块和检索质量。常用的清洗方法包括:
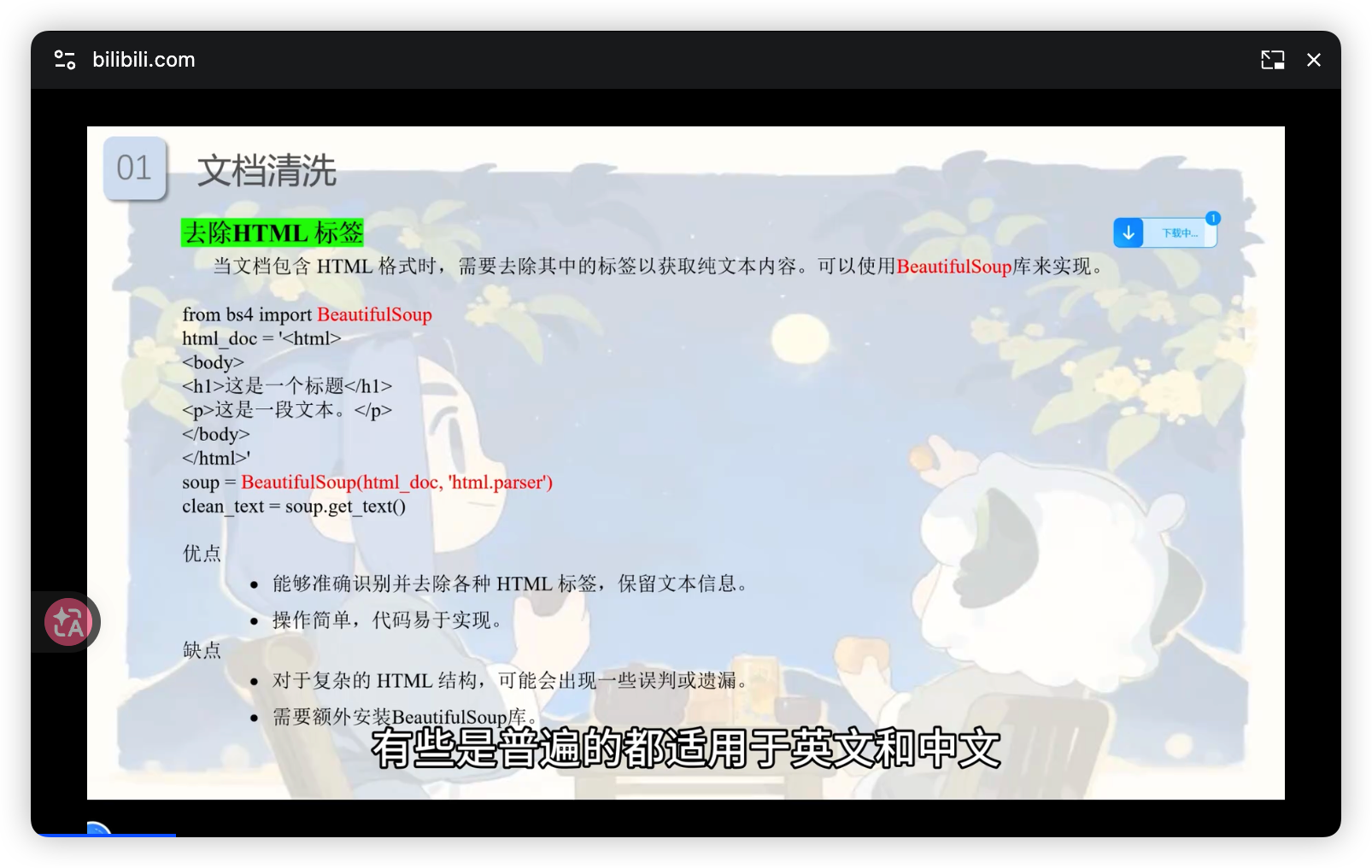
- 去除 HTML 标签:使用
BeautifulSoup库,可有效清除网页源码中的标签。难点:对复杂或非标准 HTML 结构可能出现误判或遗漏。 - 去除特殊字符/停用词:使用正则表达式或
NLTK等库的停用词列表,移除无实际语义的字符和词(如“的”、“了”、“而且”)。难点:正则规则编写需技巧,复杂规则可能影响性能;停用词列表需根据行业场景定制。 - 词干提取与词形还原:主要适用于英文,将单词还原为词根形式(如“running”还原为“run”),减少词汇变体对语义理解的干扰。难点:中文场景使用较少,英文场景下也面临“apple”(水果)与“Apple”(公司)这类专有名词大小写区分的信息丢失问题。
- 转为小写:此操作可能会丢失专有名词等重要信息,需要根据应用场景取舍。
三、 核心分块方法详解(难点)
1. 固定长度分块
- 原理:设定一个固定的 Token 数或字符数作为块大小,对文本进行均匀切割。通常会设置一个重叠长度,使相邻块有部分内容重叠,以缓解语义割裂问题。
- 优缺点:优点是简单、长度均匀;缺点是严重破坏语义连贯性,可能在句子的中间或段落的任意位置切断。
- 原文示例:固定长度分块会将语义上本应连在一起的文本强行切开。
2. 递归字符文本分割(Recursive Character Text Splitter)—— 推荐方法之一
- 原理:预设一个分隔符优先级列表
['\n\n', '\n', '。', ',', '!', '?']。算法先尝试用最高优先级分隔符切分,若结果块仍过大,则递归使用下一级分隔符继续切分。最后,将切分后的过小片段合并为符合长度要求的块。 - 优缺点:优点是最大程度利用文本天然分隔符,最有效地保持语义和段落结构的完整性,是兼顾效果与效率的常用方法;缺点是对于无标点、无段落结构的 OCR 文本效果较差,但最差情况仍能退化为固定长度分块。
- 原文示例:递归分割可以保持一个完整的功能模块输出,而固定长度分块则会将其强行切开。
3. 语义分块(Semantic Chunking)—— 效果最佳但成本最高
- 原理:
- 将文本拆分为句子。
- 使用嵌入模型为每个句子生成向量。
- 计算相邻句子的向量相似度(如使用余弦相似度)。
- 当相似度低于预设阈值时,则认为语义发生了变化,在此处进行切分。连续的高相似度句子合并为一个块。
- 难点与核心挑战:
- 阈值调参难度高:阈值设定是关键。调得过高,任何一点相关性都会合并,导致块过大;调得过低,只有极高相似度才会合,导致块过碎。需要大量实验才能找到最佳值。
- 计算成本高昂:需要对所有句子进行嵌入向量计算,且嵌入模型的选择本身就影响效果和成本。
- 扩展思考:文末提出两个值得深思的优化方向:
- 计算复用:既然分块时已为句子生成了嵌入向量,是否可与后续向量化数据库建索引的步骤进行合并,减少计算量?
- 跨段聚类:当前仅基于相邻句子合并。能否引入聚类算法,将文档中不同段落、甚至不同章节中语义相似的句子合并到一个块中,实现更高质量的“主题合并”?
4. 其他方法
- 基于文档结构的分块:非常适合 Markdown 文件,通过解析标题层级(H 1, H 2, H 3...)进行切分,能完整保留文档的层级逻辑结构。局限:仅适用于结构清晰的文档,对扫描版 PDF、HTML 等效果不佳。
- 基于特定规则/领域的分块:为法律、医疗等垂直领域定制分块规则,确保最小完整业务单元(如法律法条、病历模块)不被分割。局限:开发成本高,一套规则通常仅适配一种文档类型。
四、 元数据管理
分块后,需为每个文本块附着元数据以实现信息溯源。元数据分为几类: - 文档级:文件名、路径、创建时间、文档格式。 - 内容级:章节标题、页码、主题分类。 - 处理级:分块工具及版本、处理日志。 - 外部关联:数据库关联 ID、用户标注。
进阶思考题
- 策略选择题:假设你的知识库中有三类文档:1)结构清晰的 Markdown 技术文档;2)扫描版 PDF(通过 OCR 识别,无标点无段落);3)法律合同(条款清晰,但一条可能跨越数页)。请分别为这三类文档选择最合适的分块策略,并说明理由。
- 参数调优题:在使用递归字符文本分割器时,如何确定最佳的分隔符优先级列表?例如,对于中文技术文档,默认列表
['\n\n', '\n', '。', ',']是否最优?如果你发现文档经常在代码块和列表中间被切断,你会如何优化这个列表? - 语义分块阈值题:视频中提到语义分块的阈值难以确定。假设你正在为一个金融问答系统进行分块,请设计一个实验方案,用于确定最佳的语义相似度阈值。你需要描述你的实验数据集、评估指标以及流程。
- 计算效率题:视频末尾提出了“语义分块时的嵌入向量是否可以复用”的问题。请尝试设计一个技术方案,将句子级别的嵌入向量复用于后续的向量化建库和检索环节,并评估该方案可能带来的内存和计算开销变化。
- 元数据设计题:在一个企业客服 RAG 系统中,需要实现信息溯源功能。请为一个“退款政策”文档的文本块设计一套元数据方案,至少包含 5 个字段,并解释每个字段的用途和可能的数据来源。