目录
收起
背景
LoRA
QLoRA
背景
- 参考课程: bilibili.com/video/BV17
- 参考代码: github.com/waylandzhang
LoRA
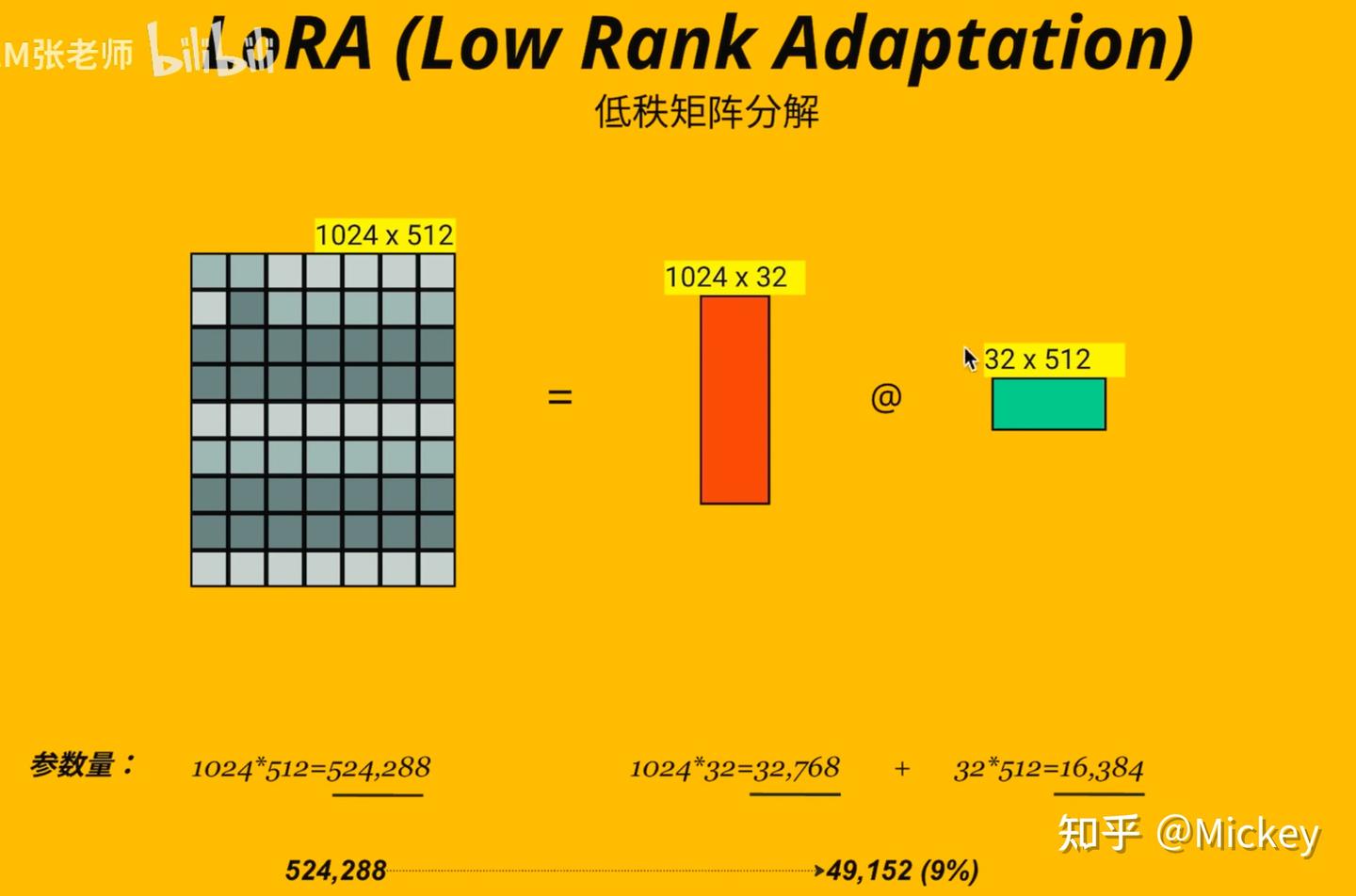
- 定义 :LoRA 即 Low-Rank Adaptation,是一种用于微调大型预训练语言模型的轻量级方法。
- 原理 :通过引入低秩矩阵来修改模型参数,只需训练少量适配器参数,如键 / 值矩阵。例如,若秩 r=8,对于特定矩阵,仅需更新 B(1024×8)+A(8×1024)=16,384 个参数,可近似减少 98% 的参数更新量,大大降低计算量。
- 适用场景 :适用于资源有限但对模型精度要求较高,且希望微调速度相对较快的场景,在大规模预训练模型的微调中能有效减少计算和存储开销
- 对比:
- 对比于全参数微调:模型参数训练前后变化是W=W+△W,参数更新直接在原始参数W上发生,参数量NxD
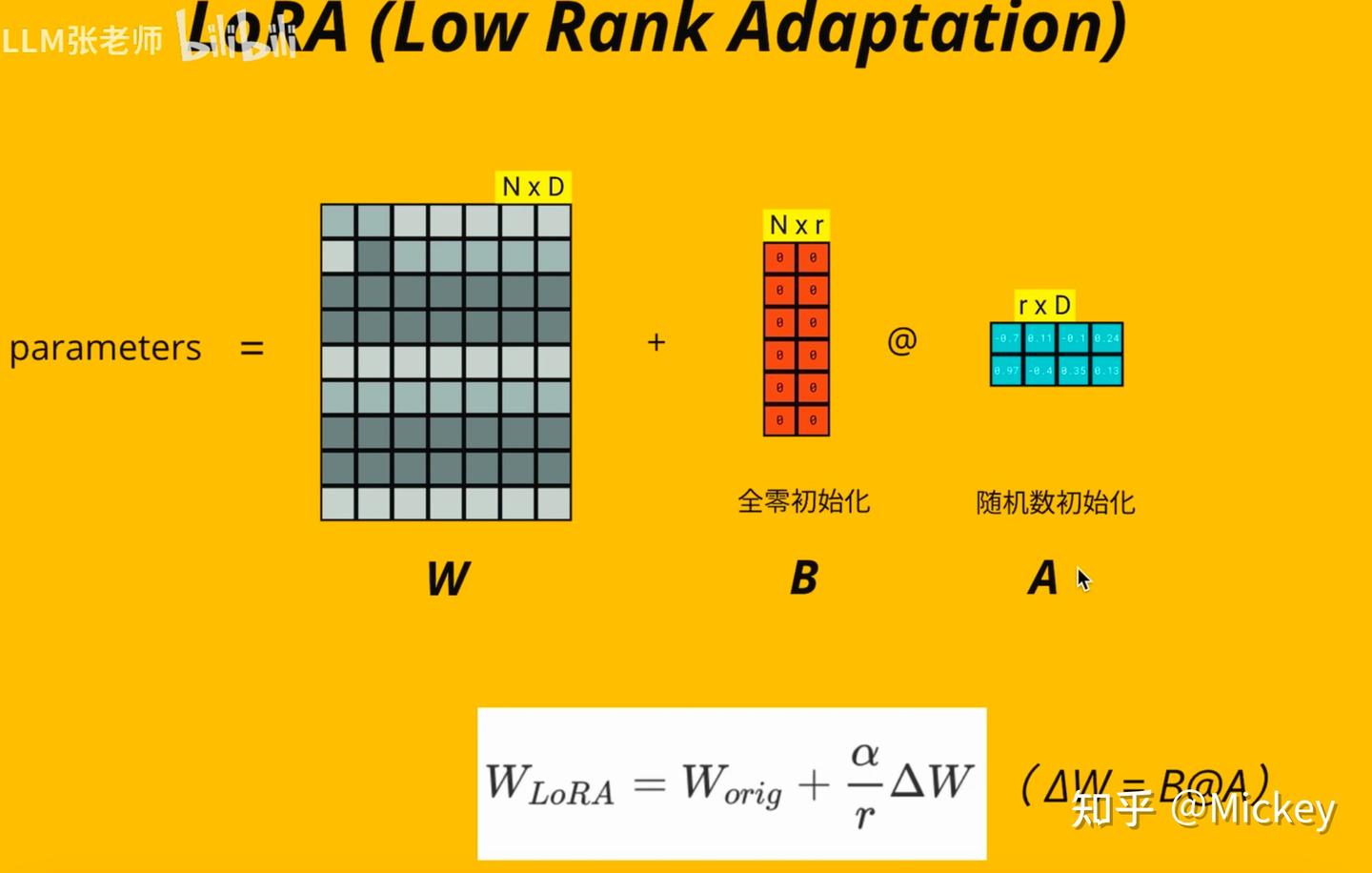
- LoRA:将原始参数W保持不变,将△W拆为两个矩阵A跟B的矩阵相乘,△W=BA,要使用新参数时再把△W跟W相加加载到模型里。
- 效果几乎等价:把参数△W压缩到两个低秩矩阵里,数学上是等价的
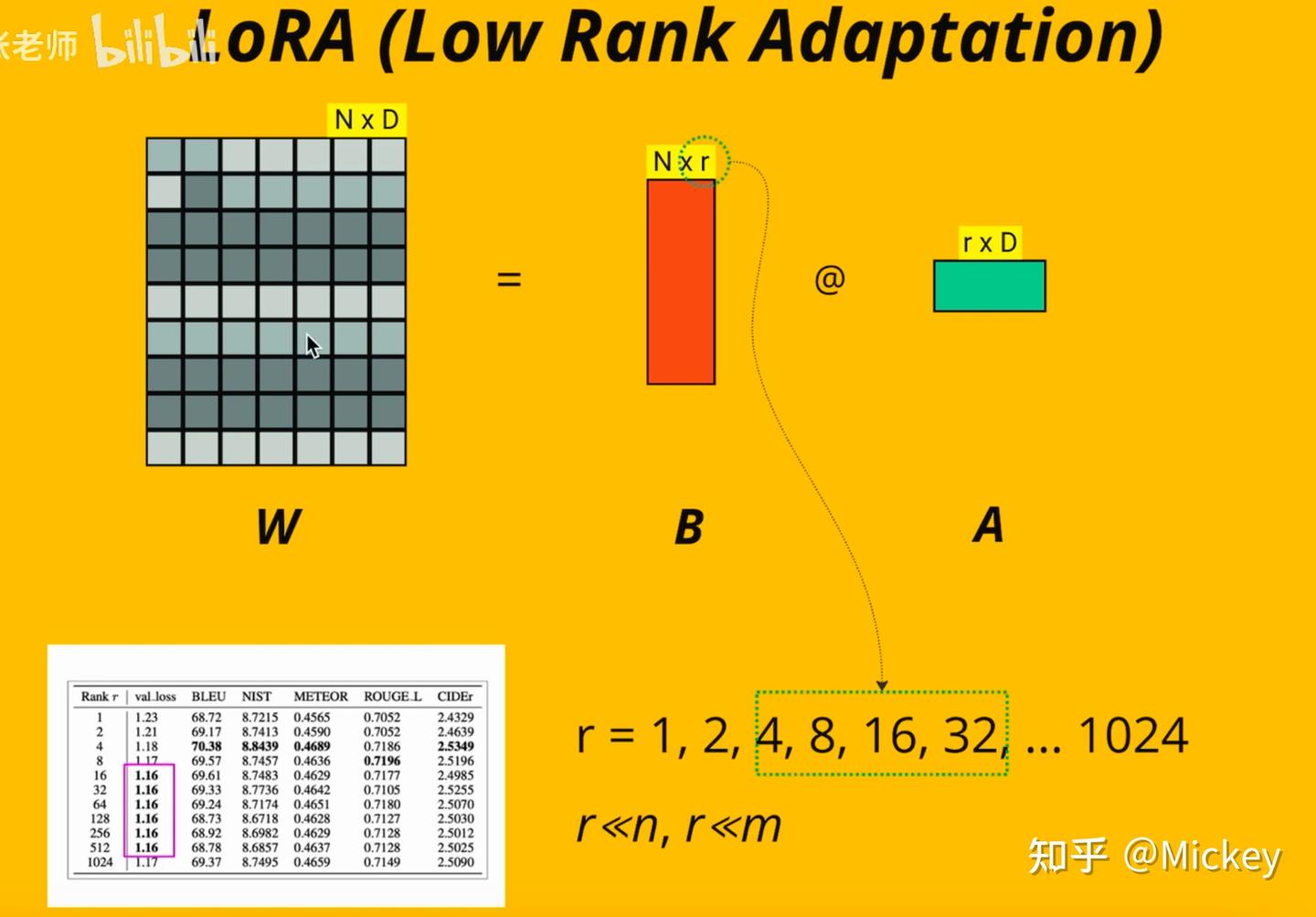
- 参数量少:是Nxr + rxD,远小于NxD,因为r<和D。LoRA的r一般选4、8、32,效果最好。
- 训练快:LoRA训练参数仅有原参数W的5~7%,训练很快
- 学习率可以调:引入alpha,作为学习率调整参数,可以减弱LoRA的更新幅度
- PEFT :parameter efficient finetune,使用PEFT可以完成LoRA微调
- alpha=1,
- r=8,
- target_modules=["q_proj", "k_proj", "v_proj", 'o_proj", "gate_proj", "up_proj", "down_proj"],指点哪些位置需要LoRA,分别是qkvo4层attention矩阵参数,gate_proj是feed forward参数,后面是输入输出矩阵
- task_type="CAUSAL_LM"

QLoRA
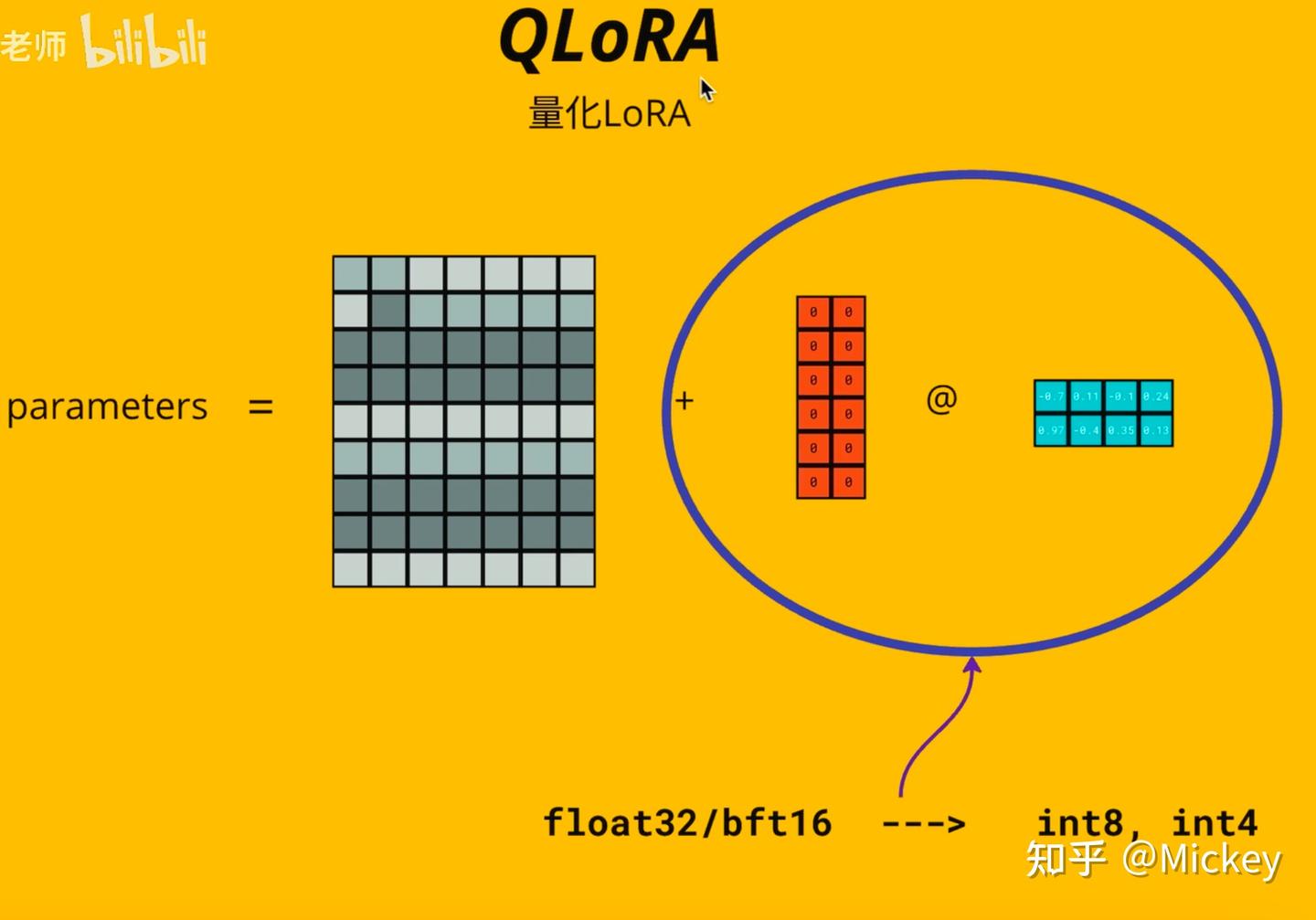
- 定义 :QLoRA 是 Quantized LoRA 的缩写,是一种结合了量化和低秩适配的参数高效微调方法。
- 原理 :在 LoRA 的基础上,将模型权重从 FP32/FP16 压缩为 4 位 NF4 (NormalFloat 4 - bit)格式,通过 Block - wise 分块量化,每块独立计算缩放因子,避免单个异常值影响整体精度。同时,采用 Paged Optimizer 分页存储梯度,将优化器状态分页存储于 CPU 内存,仅在需要时加载到 GPU,避免显存溢出。
- 优势 :能显著减少大型语言模型微调所需的内存和计算资源,使超大规模模型,如 65B 参数的模型能够在单个 GPU 上完成微调。在多项任务中,其性能接近全精度微调,例如 Guanaco 模型 采用 QLoRA 微调后可达 99.3% 的全精度微调性能
- 适用场景 :更适合对内存要求极为苛刻的场景,如在边缘设备、移动设备或显存较小的 GPU 上运行大型预训练模型,以及需要处理大规模数据但内存资源紧张的情况
- 单机单GPU训练一般用QLoRA,一张4090或A10,都可以训练 LLaMA3.

发布于 2025-07-10 11:30・浙江量化