profileName: youpingfang postId: 305 postType: post categories:
- 6
一、KV Cache:用空间换时间的推理绝招
自回归生成模式
在自回归生成中,模型根据之前的上下文(Context)预测下一个 Token。在没有缓存时,模型必须将历史上下文重复编码,每生成一个新 Token 都需要回顾并重新计算之前所有 Token 的 Key (K) 和 Value (V)。

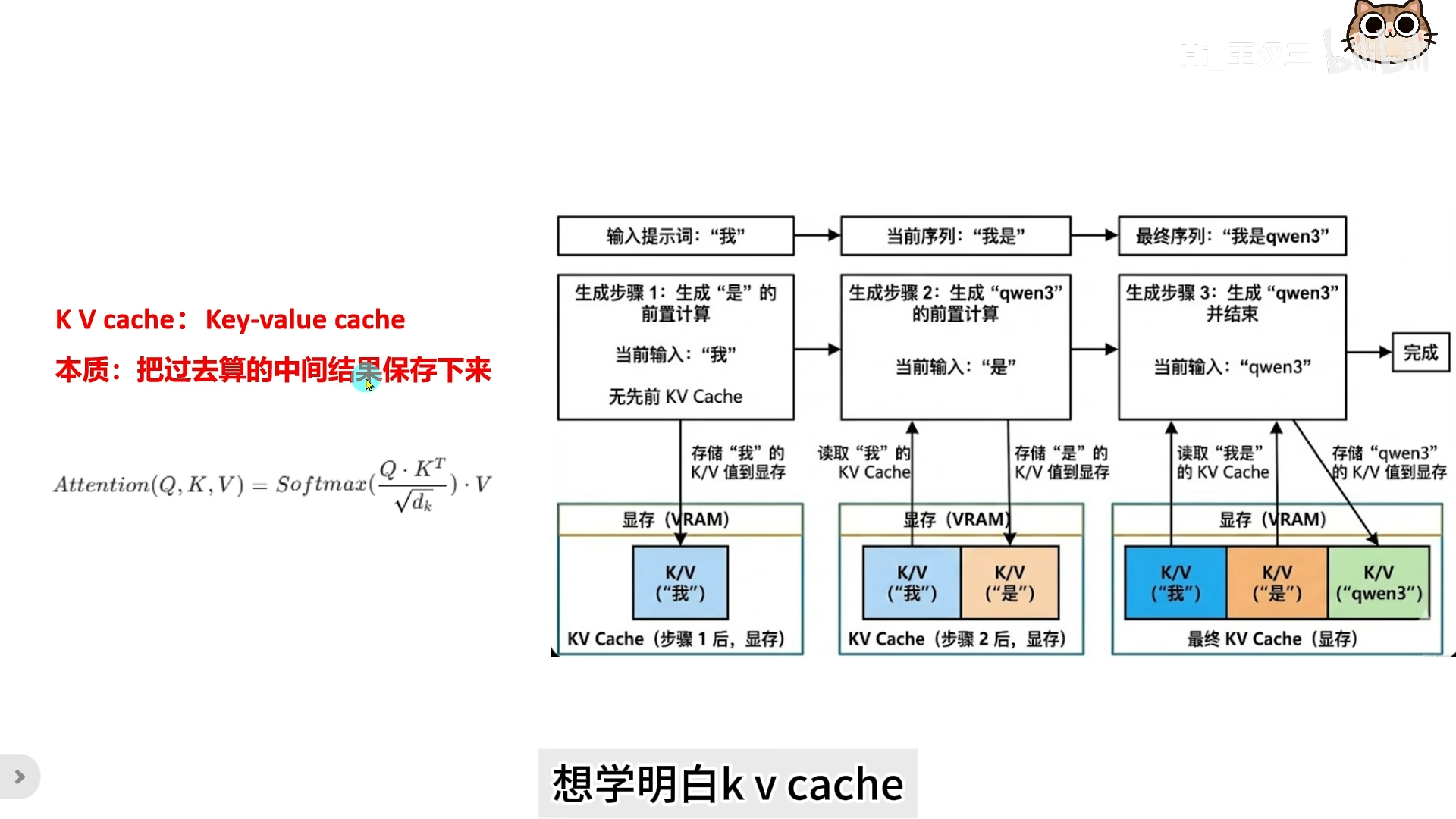
1.1 核心概念:什么是 KV Cache?
为了解决自回归生成中的重复计算问题,KV Cache 技术通过“空间换时间”的策略,将已计算过的中间结果存储起来,从而避免了大量冗余的矩阵运算,直接降低了单步推理的计算复杂度。
1.2 工作原理
KV Cache 本质上是一种缓存机制,用于存储 Transformer 模型中 Attention 层的 Key 和 Value 矩阵。在推理过程中,模型只需要计算当前新生成 Token 的 Query (Q)、Key (K) 和 Value (V),然后将新的 K 和 V 追加到缓存中。最后,利用当前的 Q 与完整的缓存(历史 K/V + 当前 K/V)进行注意力计算。
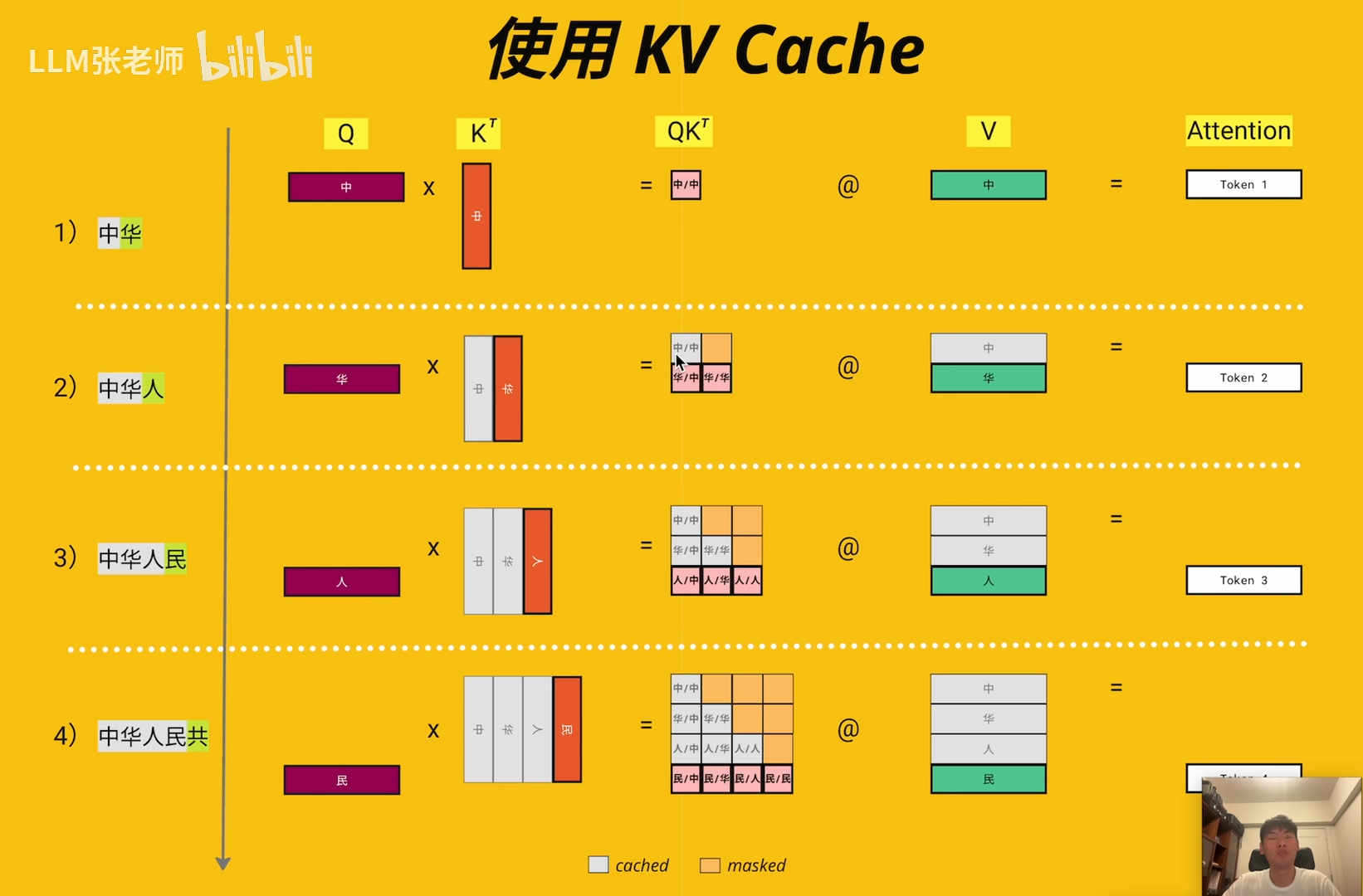 工作流程分为两个阶段:
1. Prefill 阶段(首 Token 生成):模型接收完整的 Prompt 输入,计算所有 Token 的 K 和 V 并存入 Cache,生成第一个输出 Token。
2. Decode 阶段(后续 Token 生成):模型仅接收上一步生成的 Token,计算其 Q、K、V。将新计算的 K、V 追加到 Cache 中,利用完整的 Cache 计算 Attention,生成下一个 Token,循环上述过程。
工作流程分为两个阶段:
1. Prefill 阶段(首 Token 生成):模型接收完整的 Prompt 输入,计算所有 Token 的 K 和 V 并存入 Cache,生成第一个输出 Token。
2. Decode 阶段(后续 Token 生成):模型仅接收上一步生成的 Token,计算其 Q、K、V。将新计算的 K、V 追加到 Cache 中,利用完整的 Cache 计算 Attention,生成下一个 Token,循环上述过程。
1.3 显存占用分析
自注意力公式:
$Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$。
如果没有 KV Cache,生成每个新 token 时,历史 token 的 K、V 被反复计算,效率极低。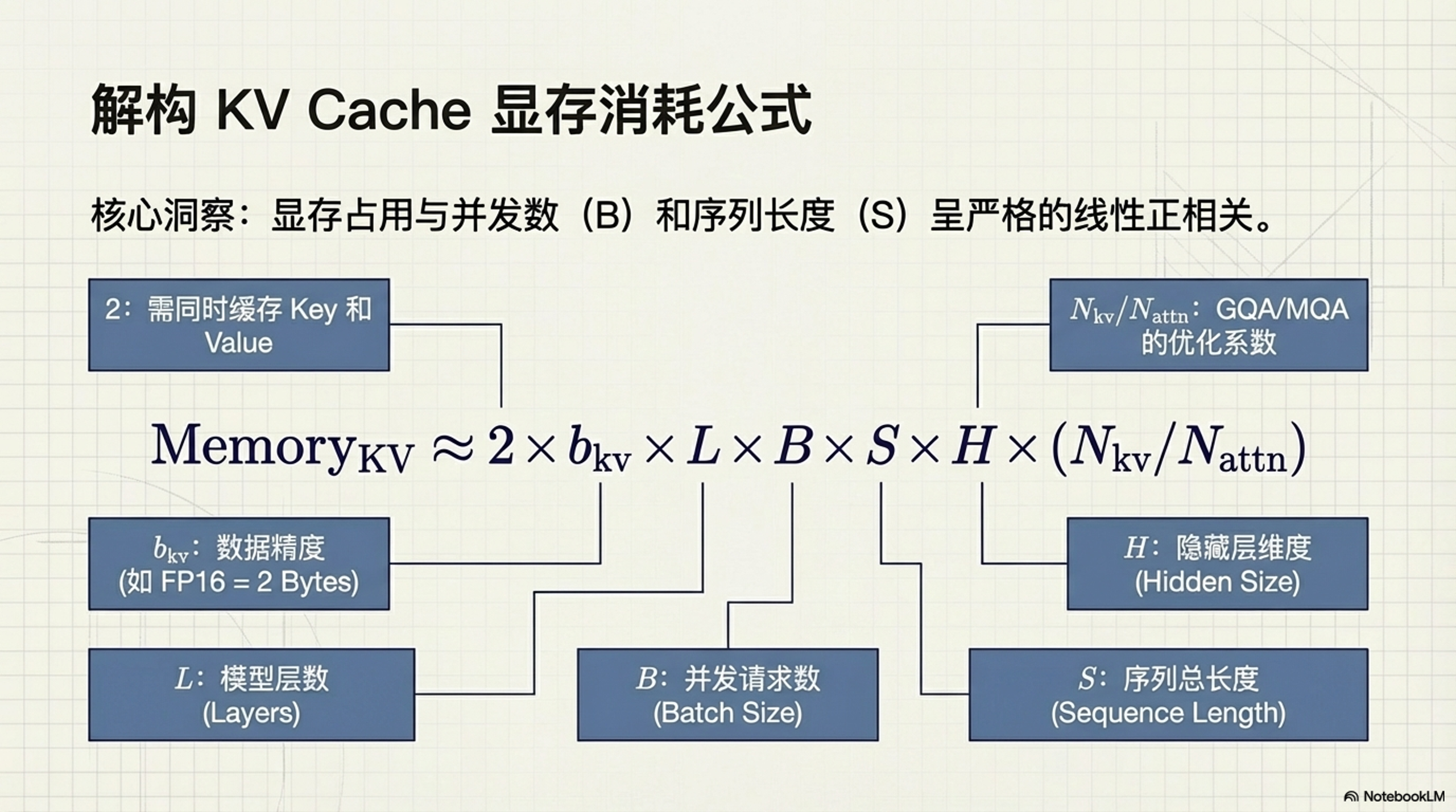
1.4 核心价值:复杂度对比
- 无 KV Cache:每生成第 $t$ 个 token,都把整个序列 $[x_1, x_2, ..., x_t]$ 重新过一遍 Transformer,复杂度为 $O(n^2)$。
- 有 KV Cache:只算当前 token 的 Q、K、V,K/V 从缓存读,复杂度为 $O(n)$。
核心价值:KV Cache 让计算量从 $O(n^2)$ 降至 $O(n)$,句子越长,加速效果越明显。
1.5 硬件瓶颈
- GPU 算力很强,但内存带宽有限。
- 朴素方式每步都要从显存反复读入整段历史的 K、V,带宽成为瓶颈,注意力变成 memory-bound 操作。
- KV Cache 把历史 K、V 留在显存,减少重复搬运,显著加速。
1.6 KV Cache 使用场景
- 训练:不用。训练时所有 token 并行计算注意力,不存在逐步生成、重复计算历史的场景。
- 推理/文本生成:用。逐 token 自回归,KV Cache 可大幅加速。
- 结论:KV Cache 是推理优化手段,训练不涉及。
1.7 为什么只缓存 K、V,不缓存 Q?
- K、V 可复用:推理时权重和输入不变,历史 token 的 K、V 是确定性的,只需计算一次,后续可永久复用。
- Q 不可复用:Q 是当前 token 的“查询”向量,每步生成的 token 不同,Q 也完全不同,缓存无用。
一句话总结:K、V 是历史的“被查询者”,只需算一次;Q 是当下的“查询者”,每步都变,缓存无用。
二、如何降低 KV Cache 开销:GQA(分组查询注意力)
2.1 背景问题
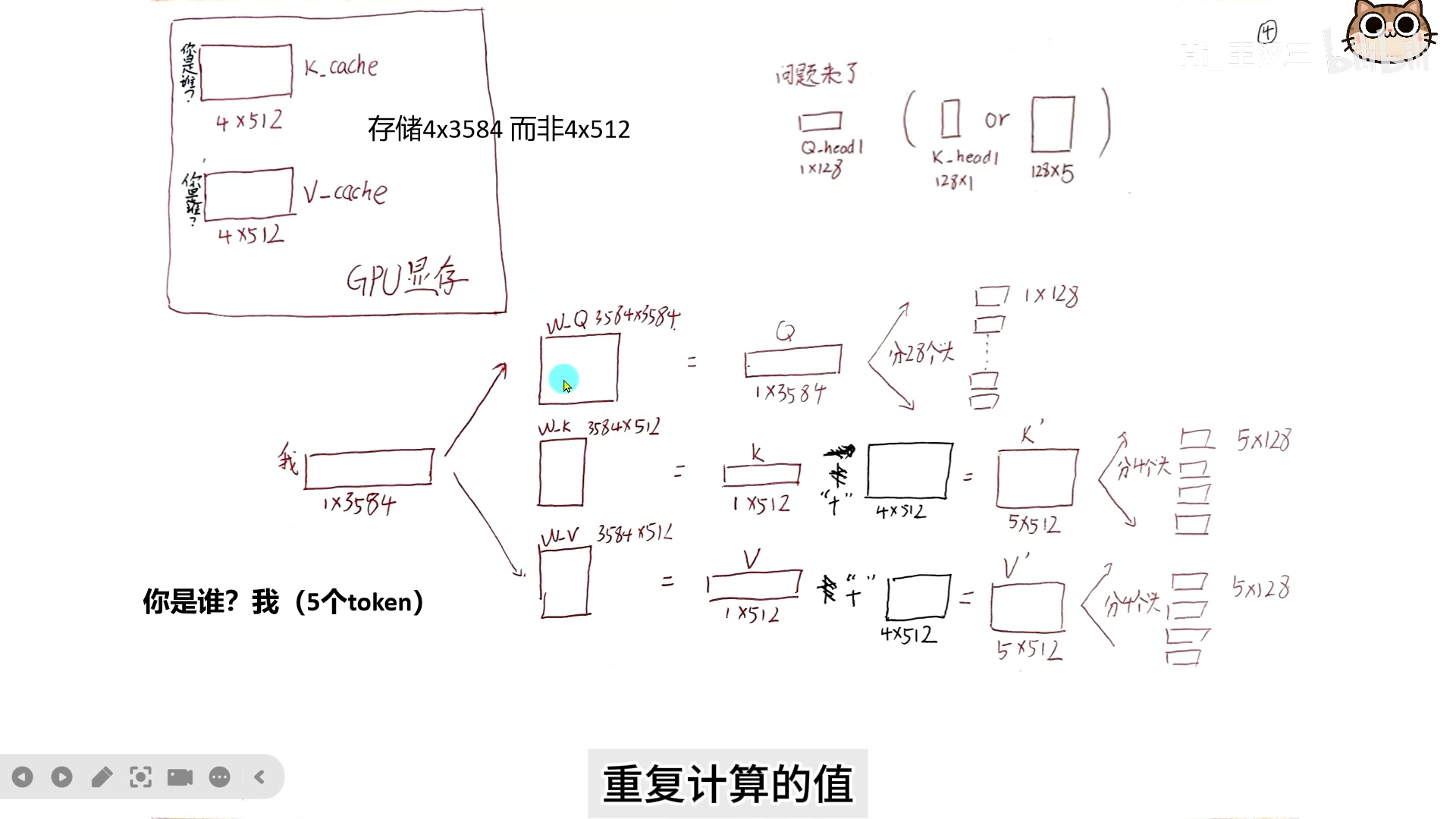
随着大模型上下文长度不断增加(如32K、128K),KV Cache 占用的显存会急剧增长,甚至超过模型权重本身。这不仅占用大量显存,更重要的是 I/O 带宽成为瓶颈,导致推理过程中卡顿、速度变慢。
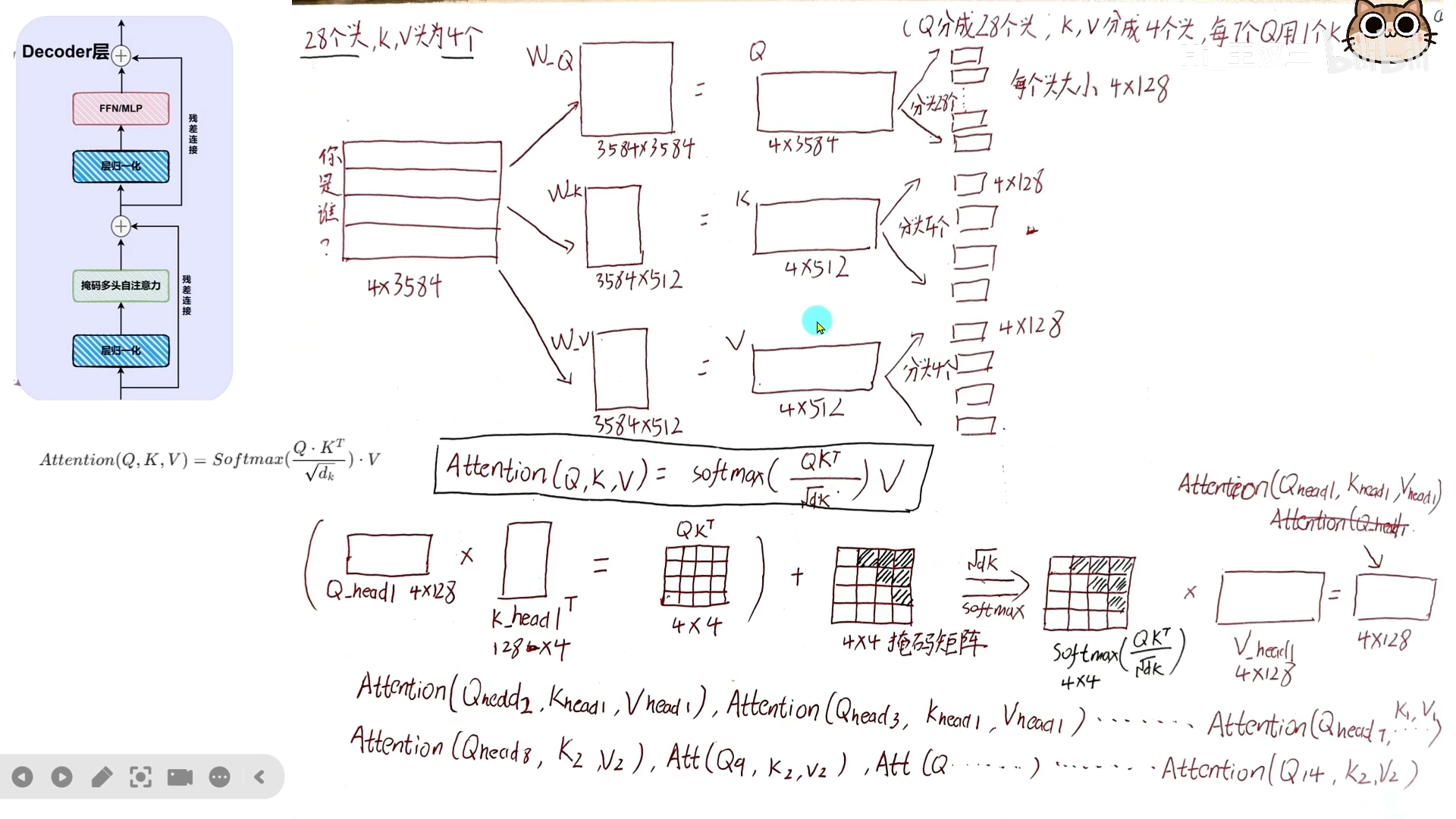
2.2 GQA 核心思想
GQA(Grouped Query Attention)的核心思想是:Query 头数远多于 KV 头数,多个 Query 头共享一组 KV 头。
以 Qwen3 为例: - Query 分成 28 个头。 - Key 和 Value 各分成 4 个头。 - 每 7 个 Query 头共享 1 组 KV 头。
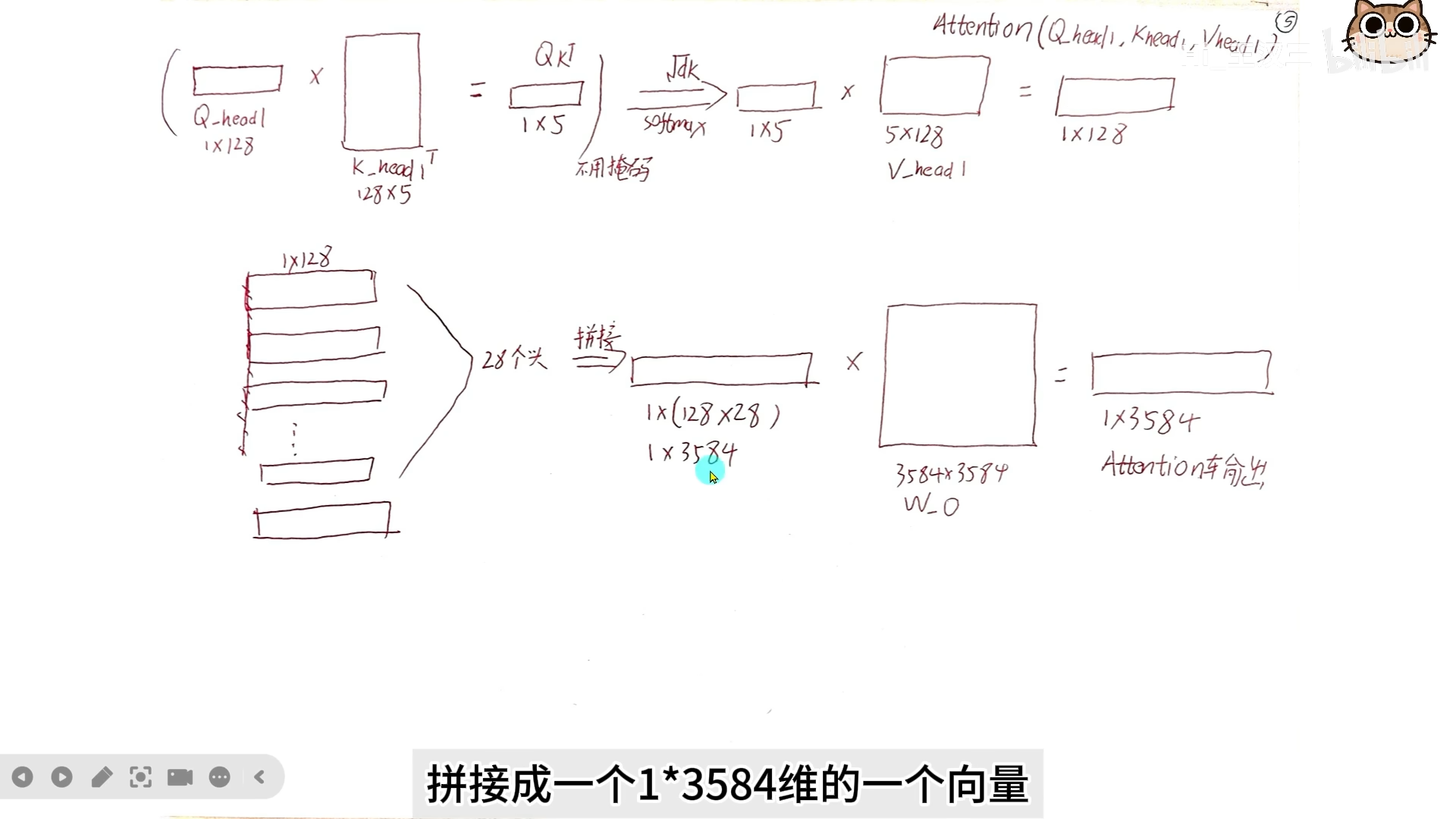
2.3 分头操作详解
假设隐藏层维度 $d{hidden} = 3584$,每个 head 维度 $d{head} = 128$: - Query 分头:切成 28 份,每份 128 维。$W_Q$ 维度为 $3584 \times 3584$。 - Key/Value 分头:各切成 4 份,每份 128 维。$W_K, W_V$ 维度为 $3584 \times 512$。 - 计算时,每 7 个 Q 头与 1 个对应的 KV 头配对计算注意力。 - 最后所有 head 的输出拼接后,通过输出权重矩阵 $W_O$ 汇总成一个向量。
2.4 显存节省分析
- MHA(多头注意力):28 个 KV 头,显存占用为 28 份。
- GQA(分组注意力):4 个 KV 头,显存占用为 4 份。
- 压缩比:约 7 倍。
GQA 在不显著损失模型精度的情况下,大幅压缩了 KV Cache 的显存占用,使得模型能够支持更长的上下文。
三、KV Cache 与 GQA 协同工作
3.1 第一轮推理(首次输入)
 1. 编码输入序列。
2. 分头:Q 分成 28 头,K、V 各分成 4 头。
3. 各 head 分别计算自注意力。
4. 预测下一个 token。
5. 缓存:将生成的 K、V 值存入显存。
1. 编码输入序列。
2. 分头:Q 分成 28 头,K、V 各分成 4 头。
3. 各 head 分别计算自注意力。
4. 预测下一个 token。
5. 缓存:将生成的 K、V 值存入显存。
3.2 第二轮推理(生成新 token)
 1. 复用缓存:从显存读取第一轮的 K、V。
2. 新 token 计算:只计算当前 token 的 K、V。
3. 拼接:新 K/V 与缓存的 K/V 沿序列维度拼接。
4. 计算注意力,输出结果。
5. 缓存更新:将新的 K、V 加入缓存。
1. 复用缓存:从显存读取第一轮的 K、V。
2. 新 token 计算:只计算当前 token 的 K、V。
3. 拼接:新 K/V 与缓存的 K/V 沿序列维度拼接。
4. 计算注意力,输出结果。
5. 缓存更新:将新的 K、V 加入缓存。
3.3 关键优化点
- 避免重复计算:无需重新计算历史 token 的 K、V。
- 显存压缩:GQA 使得 KV Cache 只存储 4 头而非 28 头,显存节省约 7 倍。
- 推理加速:计算量大幅减少,生成速度显著提升。
四、MHA、MQA、GQA 进化专题
4.1 相同点
- 都属于自注意力机制的变体。
- 都包含 Query (Q)、Key (K)、Value (V) 的线性投影。
- 都可在训练和推理中使用。
4.2 不同点
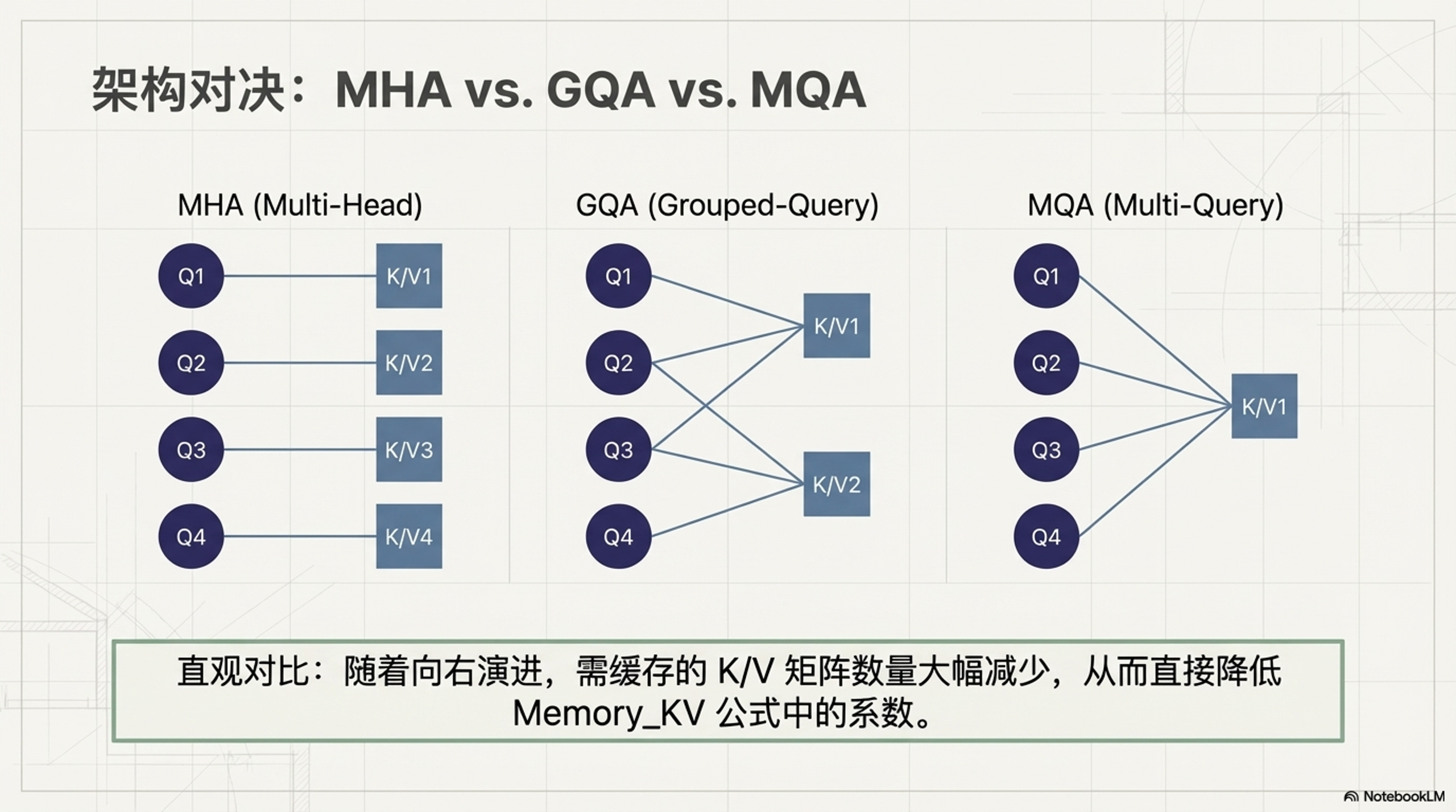
4.2.1 多头结构
- MHA:Q、K、V 都拆分成多个头,每个头独立计算注意力。
- MQA:K 和 V 只有一个头(所有 Query 头共享),Q 有多个头。
- GQA:将 K 和 V 分成 若干组,每组对应多个 Query 头。
4.2.2 计算量(FLOPs)
- 在生成阶段:MHA 计算量最大,MQA 最小,GQA 介于中间。
- 在训练阶段:三者计算量接近。
4.2.3 显存占用(尤其是 KV Cache)
- MHA:每个头都缓存 K 和 V,缓存大小为
(batch_size, num_heads, seq_len, head_dim) × 2。 - MQA:所有头共享同一份 K、V,缓存大小为
(batch_size, 1, seq_len, head_dim) × 2,显存降低约num_heads倍。 - GQA:缓存大小为
(batch_size, g, seq_len, head_dim) × 2(g 为分组数),显存占用介于 MHA 和 MQA 之间。
4.2.4 模型效果
- MHA:表达能力最强。
- MQA:表达能力下降,效果略差。
- GQA:通过分组折中,效果接近于 MHA。
4.3 总结表格
| 特性 | MHA | MQA | GQA |
|---|---|---|---|
| K、V 头数 | 等于 Q 头数(h) | 1 | 分组数 g(通常 1 < g < h) |
| 训练计算量 | 高 | 略低 | 介于中间 |
| 推理 KV Cache 显存 | 高(h 倍) | 极低(1/h) | 低(g/h) |
| 模型效果 | 最好 | 略差 | 接近 MHA |
| 适用场景 | 训练、大显存 | 极端显存受限 | 主流高效推理 |
4.4 核心概念
- MHA(Multi-Head Attention):Transformer 原生的注意力机制,将 Q、K、V 拆分为多个子空间并行处理。
- MQA(Multi-Query Attention):所有 Q 头共享同一组 K、V 头,大幅减少 KV Cache 显存占用。
- GQA(Group-Query Attention):MHA 与 MQA 的折中,将 Q 头分组,每组共享一组 KV 头。
4.5 GQA 详解
原理:将 Q 头划分为 $G$ 个组,每组内 Q 头共享一组 KV。 数学关系: - 分组数 $G$ = Q 头数 → 等价于 MHA - 分组数 $G$ = 1 → 等价于 MQA
4.6 总结
三种注意力机制代表不同的设计权衡: - MHA:表达能力最强,显存占用最高,适合训练阶段。 - MQA:显存占用最小,推理效率最高,但表达能力下降明显。 - GQA:在表达能力与显存效率之间取得平衡,已成为大模型推理优化的主流选择。
MQA 与 GQA 提出的根本目的是解决大模型推理时的 KV Cache 瓶颈,该瓶颈不仅涉及显存占用,还涉及显存带宽瓶颈。
面试题与答案
Q1:什么是 KV Cache?它的作用是什么?
A1:KV Cache 是 LLM 推理阶段的核心加速技术。它通过存储已计算的 Key 和 Value 矩阵,避免每次生成新 token 时重复计算历史 token 的 K、V,从而大幅提升推理速度。
Q2:KV Cache 面临的最大挑战是什么?
A2:显存瓶颈。随着上下文长度增加,KV Cache 占用的显存急剧增长,不仅占用大量显存,更重要的是 I/O 带宽成为瓶颈,导致推理卡顿。
Q3:什么是 GQA?它是如何实现显存优化的?
A3:GQA(Grouped Query Attention)将 Q 头分成多个组,每组内的 Q 头共享一组 K、V 头。通过减少 KV 头的数量(从 h 减少到 g),将 KV Cache 的显存占用降低为 MHA 的 g/h,在模型表达能力和显存效率之间取得平衡。
Q4:MHA、MQA 和 GQA 的本质区别是什么?
A4:它们在 K、V 头的数量上不同。 - MHA:每个 Q 头拥有独立的 K、V 头(数量为 h)。 - MQA:所有 Q 头共享同一个 K、V 头(数量为 1)。 - GQA:将 Q 头分组,每组共享一个 K、V 头(数量为 g, 1 < g < h)。
Q5:为什么只缓存 K 和 V 而不缓存 Q?
A5:K、V 在推理时是确定性的,可被后续步骤复用。而 Q 是当前步的“查询”向量,每一步都会改变,缓存 Q 没有意义。