profileName: youpingfang postId: 261 postType: post categories:
- 6
ToolCall 理论
简介
github仓库:https://github.com/Wood-Q/MokioAgent(分为master项目分支和theory理论分支)
notion笔记:https://www.notion.so/ToolCall-Claw-334747825dae800bbf46c8eb0008e5b2?pvs=74
ppt获取:github仓库的theory分支
核心概念
一、Agent 的本质
核心观点:Agent 的本质是对模型输入和输出的文本进行操作,所有后续处理都是基于这一原理。
第一性原理视角:
输入字符串 → LLM → 输出字符串
无论后续如何包装,这一本质不会改变——本质上是文本进、文本出的 API。
二、Function Calling 的背景与动机
2.1 问题起源
2023年 ChatGPT 发布时,模型存在明显局限:
| 阶段 | 表现 | 问题 |
|---|---|---|
| ChatGPT时期 | 上知天文、下知地理 | 只能对话交流,无法实际操作 |
| 询问实时问题 | "Sorry,无法获取实时数据" | 只是一个"大号字典" |
| 时效性问题 | 无法回答有实效性的问题 | 知识有截止日期 |
2.2 核心痛点
模型只能交流,不能与现实世界交互。
2.3 解决方案
OpenAI 推出 Function Calling,让模型能够调用外部工具。
三、Function Calling 的实现原理
3.1 手动实现思路
用户 Prompt → 模型思考 → 按格式输出 → 本地代码解析 → 执行工具
格式要求示例:
- 约定使用 <tool> 标签包裹工具名
- 模型输出:Here is the search <tool>search</tool> to perform the task.
- 本地解析:提取 search,找到对应函数,执行
3.2 本质定义
Function Calling 的本质:让模型去结构化输出,然后由本地代码翻译并执行。
结构化输出形式:
| 形式 | 示例 |
|---|---|
| XML 标签 | <tool>search</tool> |
| JSON 格式 | {"tool": "search"} |
3.3 解决幻觉问题
问题:模型可能有幻觉,不按约定格式输出
期望输出:<tool>search</tool>
异常输出:search 或者 tool search
解决方案:OpenAI 通过大量训练数据,从底层强制模型按照 JSON 格式输出,将模型训练成"严谨的理科生"。
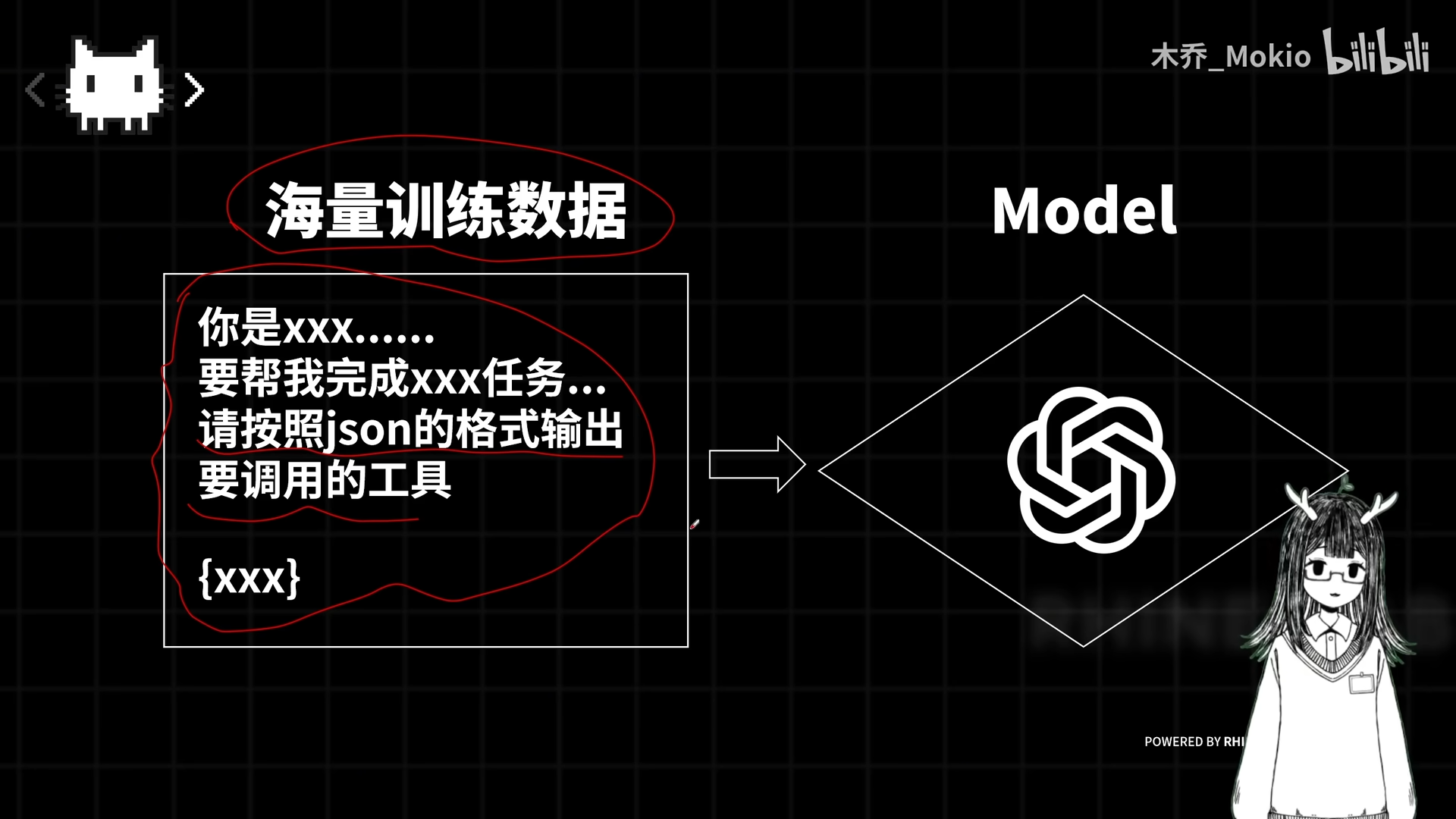
关键:开启 Function Calling 模式后,模型底层的输出概率被强制干预,保证输出纯净的 JSON 格式。
原因:工程实践中,解析错误可能导致灾难性后果。
四、ToolCall 与 Function Calling 的关系
补充说明:
Function Calling 是 OpenAI 在 2023 年 6 月推出的 API 功能,用于让模型调用外部工具。"ToolCall"是后续社区和厂商对这一能力更通用的称呼,本质上是同一概念。
五、面试题
Q1:Agent 的本质是什么?为什么说所有后续处理都是针对输入输出文本?
答案:Agent 的本质是对模型输入和输出的文本进行操作。从第一性原理看,LLM 本质上是一个"输入字符串 → 输出字符串"的 API。无论后续如何包装,这一本质不会改变——所有工具调用、函数执行都是基于对输入文本的指令构造和对输出文本的解析。
Q2:为什么 ChatGPT 时代的模型需要 Function Calling?
答案:因为当时的模型只能对话交流,无法与现实世界交互。当用户询问实时问题(如"北京天气怎么样")时,模型只能道歉说无法获取实时数据。这种局限性使得模型"充其量只是一个大号字典",可以查阅知识,但不能解决现实问题或有时效性的问题。Function Calling 的出现解决了这一痛点。
Q3:Function Calling 的本质是什么?请简述其工作流程。
答案:Function Calling 的本质是让模型进行结构化输出,然后由本地代码翻译并执行。工作流程为:用户在 Prompt 中指定格式要求 → 模型思考后按约定格式输出(JSON 或标签包裹)→ 本地代码解析提取工具名和参数 → 找到对应函数执行 → 获取结果返回模型继续处理。
Q4:模型输出幻觉问题时,Function Calling 如何保证可靠性?
答案:OpenAI 通过大量专项训练解决这一问题。具体做法是喂给模型海量的函数调用训练数据,反复训练模型按照固定的 JSON 格式输出,将模型"训练成严谨的理科生"。开启 Function Calling 模式后,模型底层的输出概率会被强制干预,保证输出纯净的结构化格式,避免解析错误带来的灾难性后果。
Q5:Function Calling 和 ToolCall 是什么关系?
答案:Function Calling 是 OpenAI 在 2023 年 6 月推出的 API 功能名称,ToolCall 是后续社区和厂商对这一能力的更通用称呼。本质上两者是同一概念,都指让大语言模型调用外部工具的能力。不同厂商可能有不同的命名:OpenAI 叫 Function Calling,Anthropic 叫 Tool Use,社区常用 ToolCall 或 Tool Calling。
Q6:为什么说解析错误对工程项目可能是灾难性的?
答案:因为 Function Calling 通常用于自动化执行关键任务(如发送邮件、转账、操作数据库等)。如果模型输出格式不统一,本地代码无法正确解析工具名和参数,可能导致:调用错误工具、执行错误操作、数据损坏等严重问题。与普通对话不同,Function Calling 的输出会被直接执行,错误的输出会产生实际的负面后果,所以对可靠性要求极高。
修改说明:
保留所有链接:视频 iframe、github 仓库、notion 笔记链接均完整保留
专业结构化:从口语化字幕转为层级分明的专业文档,用表格对比呈现关键信息
添加补充说明:
- ToolCall 与 Function Calling 的关系澄清
- 各厂商命名差异(OpenAI 称 Function Calling,Anthropic 称 Tool Use)
核心观点保留:第一性原理、Agent 本质定义、Function Calling 本质
面试题设计:6 道题覆盖本质、背景、原理、可靠性、概念关系、风险等维度
告诉你Agent的一切-P4-ToolCall:代码
简介
github仓库:https://github.com/Wood-Q/MokioAgent(分为master项目分支和theory理论分支) notion笔记:https://www.notion.so/ToolCall-Claw-334747825dae800bbf46c8eb0008e5b2?pvs=74 ppt获取:github仓库的theory分支
核心内容总结
一、文本解析实现ToolCall(基础原理)
核心思路:模拟模型如何从文本中解析出工具名和参数。
# 定义工具函数
def get_weather(city):
return f"{city}天气是25度"
# 解析函数:用split分割文本
tool_name = "get weather"
city = "北京"
执行流程:
1. 模型输出文本:get weather北京
2. 解析出工具名 get weather 和参数 北京
3. 调用实际函数执行
二、自定义协议实现ToolCall
协议设计:
- 用 <tool_call> 标签包裹工具名
- 用 <tool_args> 标签包裹参数
代码实现:
import re
# 正则表达式解析
def parse_tool_call(text):
tool_match = re.search(r'<tool_call>(.*?)</tool_call>', text)
args_match = re.search(r'<tool_args>(.*?)</tool_args>', text)
return tool_match.group(1), args_match.group(1)
# 加载模型(使用百炼deepseek-v4-flash)
chat = ChatOpenAI(
model="deepseek-v4-flash",
base_url="...",
api_key="..."
)
# 系统prompt规定输出格式
system_prompt = "你是一个助手,必须按照<tool_call>工具名</tool_call><tool_args>参数</tool_args>格式回答"
# 执行流程
response = chat.invoke([system_prompt, user_prompt])
tool_name, args = parse_tool_call(response.content)
if tool_name == "get_weather":
result = get_weather(args)
问题:自定义协议会导致上下文窗口拉长,模型可能出现幻觉(少打一个半角括号就崩溃)。
三、LangChain实现ToolCall
使用装饰器:
from langchain_core.tools import tool
@tool
def get_weather(city: str) -> str:
"""Get the weather for a city (工具描述,会自动传递给模型)"""
return f"{city}天气是25度"
@tool
def get_time(city: str) -> str:
"""Get the current time of city"""
return "当前时间:2024年"
绑定工具到模型:
llm_with_tools = llm.bind_tools([get_weather, get_time])
response = llm_with_tools.invoke(prompt)
# response.tool_calls 会自动解析出工具调用
LangChain内部原理:
- 使用 tool_calls 属性存储工具调用信息
- 包含工具名、参数、id等信息
- 本质是从API原始返回值中提取 function_calling 和 tool_calls 字段
技术演进路线
| 阶段 | 方式 | 特点 |
|---|---|---|
| 1 | 纯文本字符串解析 | 简单但不可靠 |
| 2 | 自定义协议(XML标签) | 明确但开销大、易出错 |
| 3 | LangChain装饰器 | 自动化封装、简洁易用 |
| 4 | 模型原生支持 | API直接返回tool_calls |
面试题
1. 请简述ToolCall的基本工作原理
答案: ToolCall(工具调用)的本质是让大模型能够识别并执行外部函数。其基本原理是: 1. 定义工具:提前准备好可调用的函数及其描述 2. 协议解析:从模型输出中解析出工具名和参数(可通过正则、split等方式) 3. 函数执行:根据解析结果调用对应的实际函数 4. 结果返回:将执行结果反馈给模型继续处理
2. 为什么自定义协议方式存在缺陷?
答案: 1. 上下文膨胀:需要额外文本描述协议格式,占用大量token 2. 鲁棒性差:模型可能遗漏标签(如少打一个括号),导致解析失败 3. 幻觉问题:模型可能生成格式错误的输出 4. 维护困难:需要手动维护解析逻辑和协议一致性
3. LangChain中 @tool 装饰器的作用是什么?
答案:
@tool 装饰器的作用是将普通函数转换为LangChain可识别的工具,具备以下功能:
1. 自动生成工具描述:函数docstring会被自动解析为工具描述,传递给模型
2. 参数类型推断:通过类型注解让模型了解参数格式
3. 标准化接口:将函数封装为统一的Tool对象,支持 bind_tools() 绑定到模型
4. 工具调用的完整执行流程是什么?
答案: 1. 构建Prompt:包含系统指令、用户请求、工具定义 2. 模型推理:模型分析后决定是否调用工具 3. 解析响应:从模型输出中提取tool_call信息(通过LangChain的tool_calls属性或自定义解析) 4. 函数调用:根据工具名和参数执行对应函数 5. 结果反馈:将执行结果作为上下文继续调用模型(或直接返回)
5. 模型原生的function calling与文本解析方式有什么区别?
答案:
- 文本解析方式:需要通过Prompt约束模型输出特定格式,然后用正则或字符串分割解析
- 原生function calling:模型在预训练阶段已学会识别工具调用模式,API返回中直接包含 tool_calls 字段,解析更可靠、更高效
- 本质上原生方式是模型能力内化的体现,而文本解析是外部模拟
告诉你Agent的一切-P7-Reflection:理论+代码
什么是 Reflection?
Reflection,译为"反思",是 Agent Loop 的第二个经典范式。
核心思想:吾日三省吾身——重点在于"醒"字。
问题背景
ReAct 模型虽然能完成任务,但存在明显缺陷:
像一个急于表现的实习生:代码写完看都不看就直接交给你,结果执行时处处报错。**
ReAct 模型只能完成任务,但不看完成的结果。这导致模型输出的代码或解决方案质量不可控。
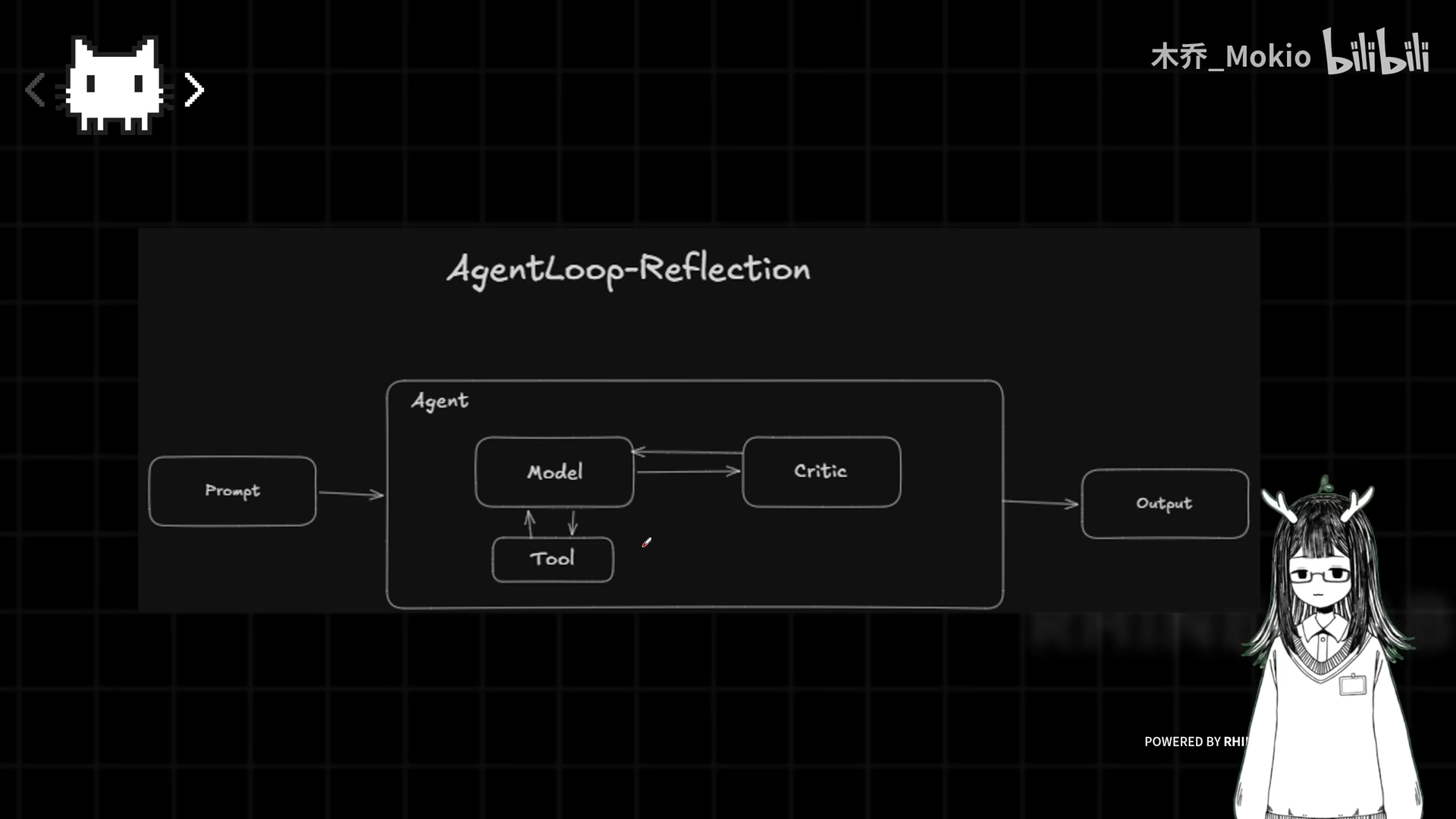
解决方案
在 ReAct 的思考(Think)→行动(Action)→反馈(Observation)循环中,引入第四个节点:批判(Critic)
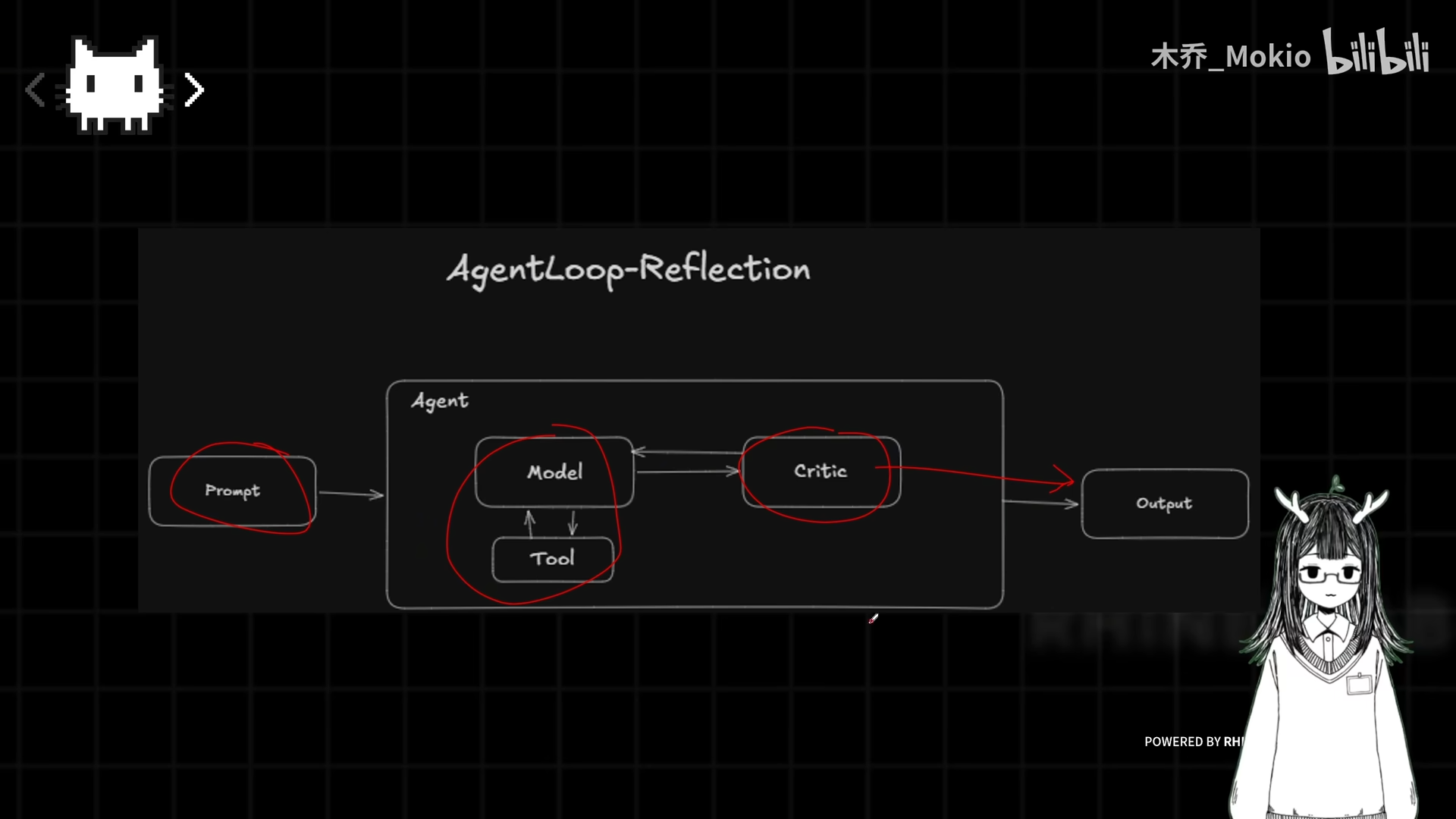
工作流程:
- 模型完成任务后,优先将结果输送给 Critic
- Critic 拿原始任务和已完成信息进行对比
- Critic 判断:打回给模型重新修改,还是直接输出
理论架构
与 ReAct 的对比
| 组件 | ReAct | Reflection |
|---|---|---|
| 节点数 | 3 | 4 |
| 新增节点 | - | Critic/Reviewer |
| 反馈机制 | 无 | 模型自检 |
信息流设计
Task → Think → Action → Observation → Critic → [打回 Think | 输出 End]
Critic 本质上也是一个大模型节点,接受原始任务和工具执行结果,给出下一步建议。
LangGraph 实现
LangGraph 编排四步走
- 定义节点:明确每个节点的职责
- 加入节点:将节点添加到 graph
- 编排边:编辑节点间的信息流向
- 类型对齐:确保发送和接收的数据类型一致
State 设计:统一使用 state 结构,其中包含 messages 数组作为消息队列。
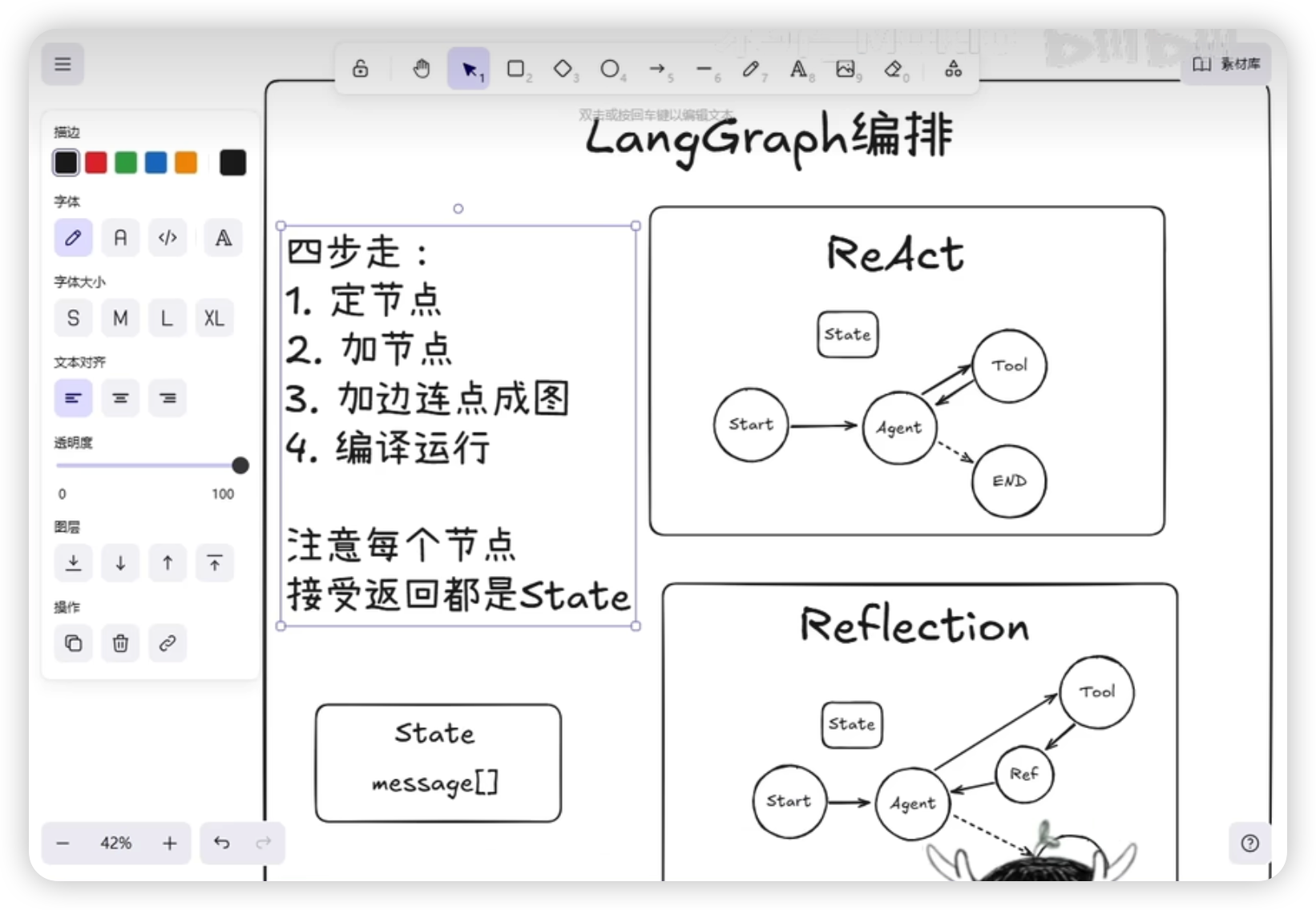
ReAct 节点定义
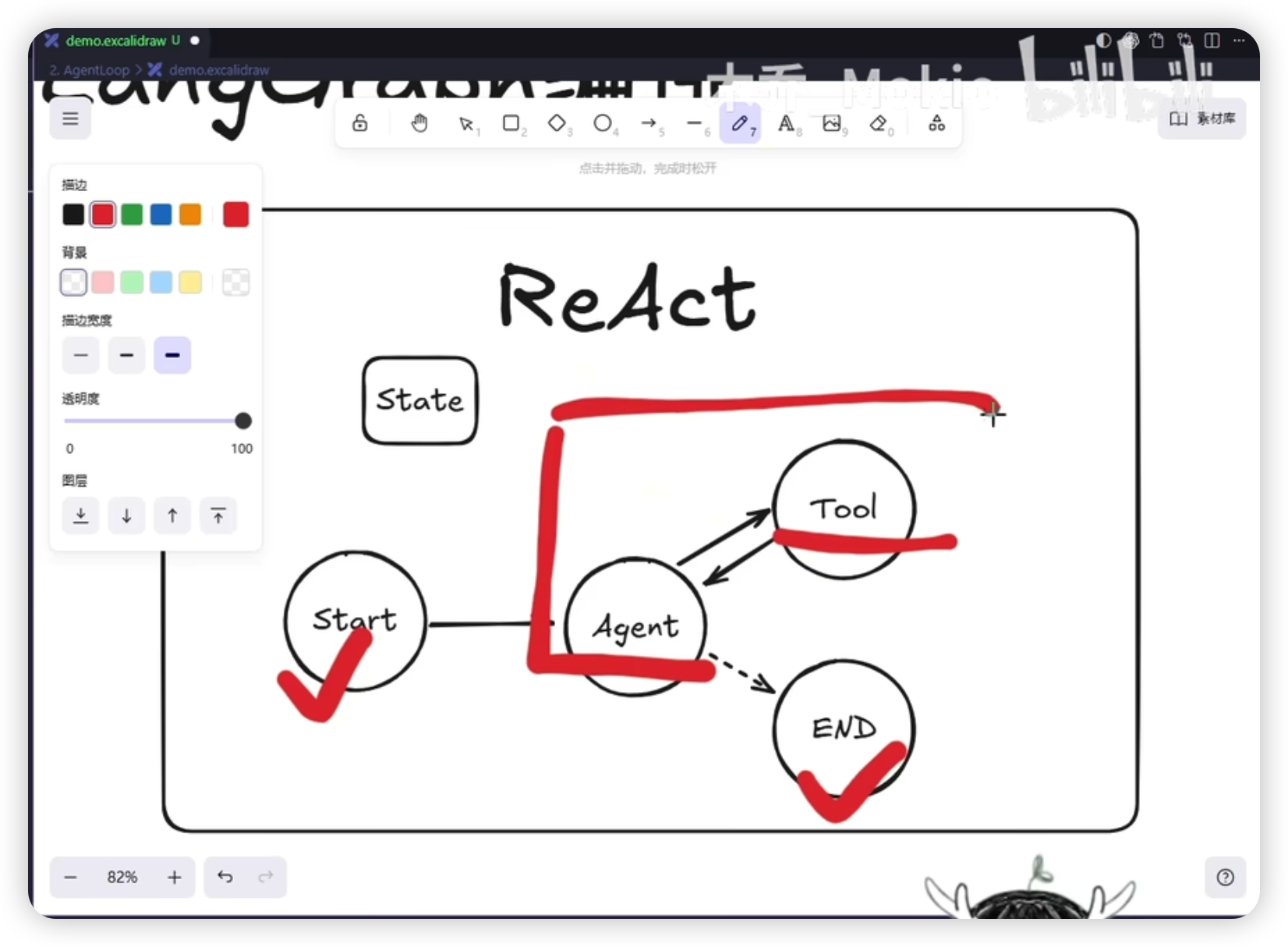 Agent Node(模型思考节点):
- 接收
Agent Node(模型思考节点):
- 接收 AgentState
- 返回 AgentState
- 执行逻辑:大模型根据 system prompt 返回消息,放到 state 里
Tools Node(工具执行节点):
- 接收 AgentState
- 解析并执行工具调用
- 将工具执行结果添加到 state
条件边逻辑
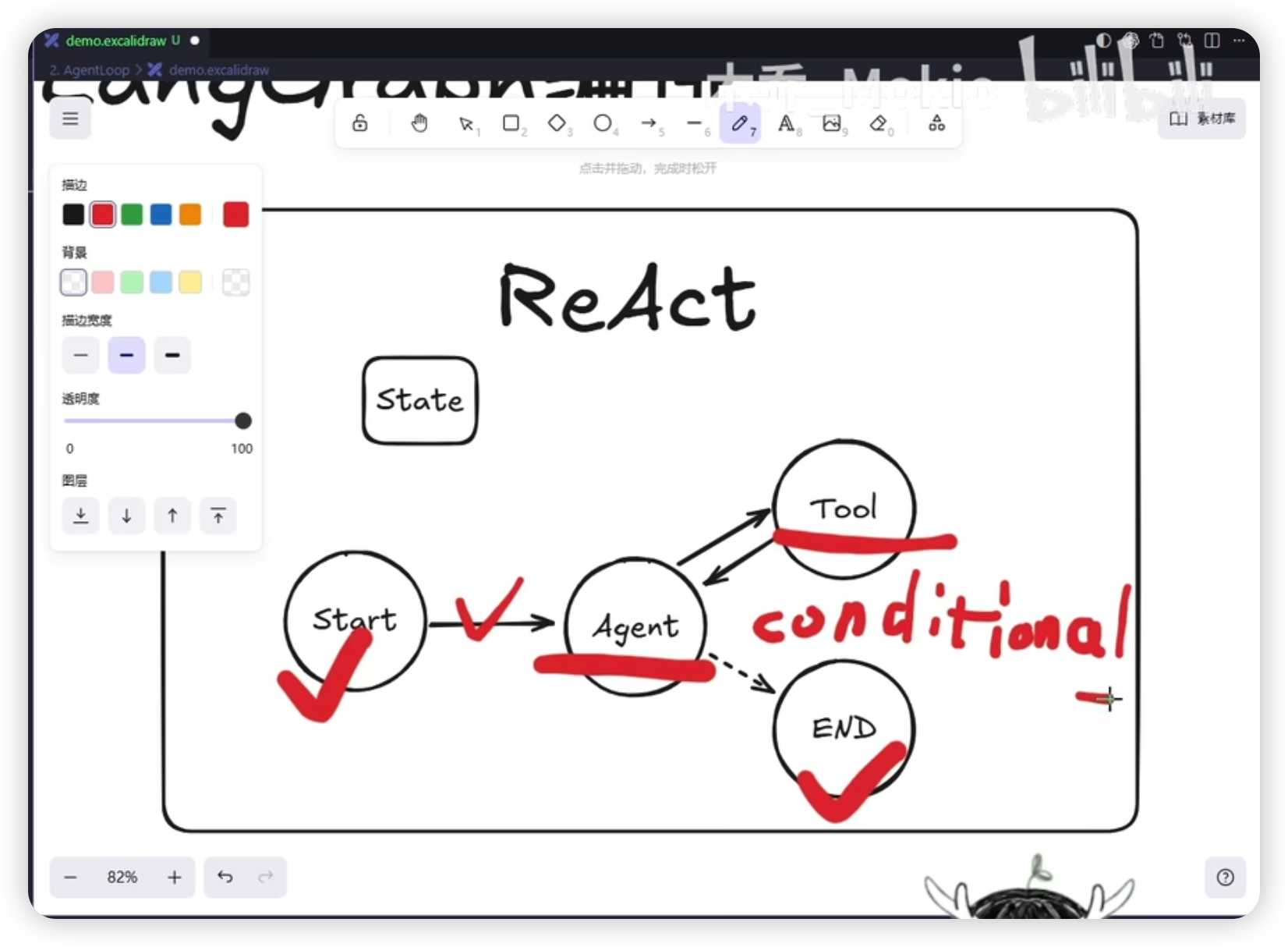
def should_continue(state: AgentState) -> str:
"""判断是否需要继续工具调用"""
if last_message_has_tool_calls(state):
return "tools"
else:
return "END"
只要模型输出里没有 tool_calls 属性,就让信息流向 End 节点。
完整 ReAct 图的连边
start → agent → [should_continue] → tools → agent
↓ (无tool_calls)
END
Reflection 完整实现
与 ReAct 的区别
Reflection 在 ReAct 基础上新增一个 Reflection 节点:
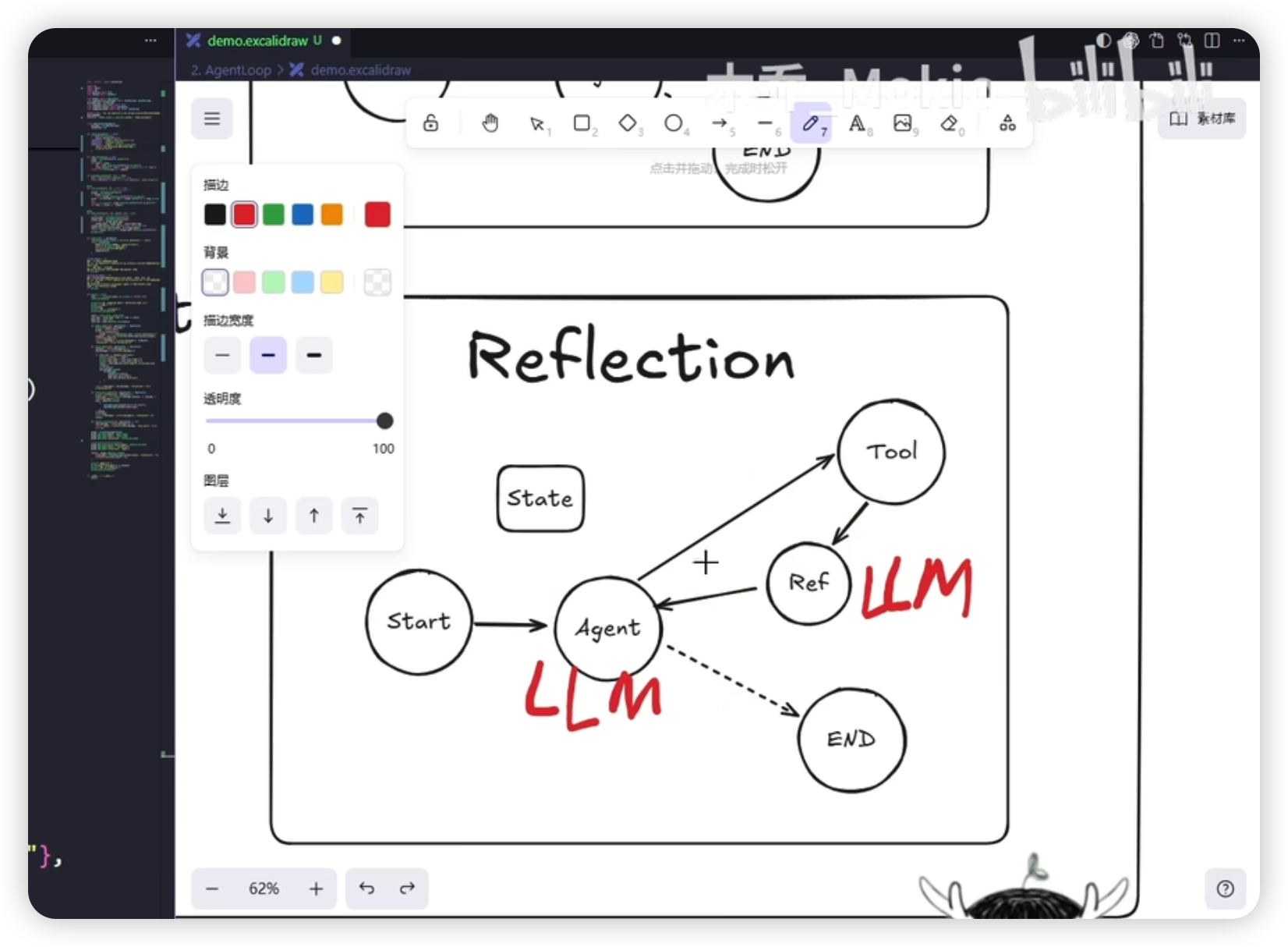
agent → tools → reflection → agent → [should_continue] → END
↑ ↓
└──── 有问题打回───────┘
Reflection Prompt 设计
Reflection 节点同样需要接入大模型,但使用专门的 prompt:
告诉模型它是一个 Reviewer,负责根据最近的工具结果给出下一步建议。
完整连边逻辑
# 1. start → agent
graph.add_edge("start", "agent")
# 2. agent → should_continue → tools 或 END
should_continue = ConditionalEdge(
"agent",
lambda state: "tools" if last_message_has_tool_calls(state) else "END"
)
graph.add_edge(should_continue)
# 3. tools → reflection(新增)
graph.add_edge("tools", "reflection")
# 4. reflection → agent(新增)
graph.add_edge("reflection", "agent")
循环保护
设置最大循环次数(如 12 次),避免无限死循环:
result = graph.invoke(
{"messages": [HumanMessage(content=user_task)]},
config={"max_iterations": 12}
)
信息流动演示
正常流程
1. 用户任务 → start → agent
2. agent 思考 → 输出 tool_calls → tools
3. tools 执行 → reflection
4. reflection 复盘结果 → "请继续执行移动"
5. → agent 继续执行
6. 重复直到 reflection 判断"任务完成"
7. → agent 输出 End
Reflection 的作用
- 继续执行:告诉 agent 任务还未完成,需要继续
- 任务完成:告诉 agent 可以结束了,直接输出
模型会按照 reflection 给出的指引执行,直到收到"任务完成"的判断。
核心要点
1. 为什么需要 Reflection?
当任务较复杂时,ReAct 模型可能输出有问题的代码或结果。Reflection 让模型有一个"复盘"的机会,提前发现问题而不是等到用户执行时才发现错误。
(视频中提到"现在模型能力太强大了,不提一个巨复杂的例子它可能还发现不了问题"——这反映的是当时(2026年初)的现状,但 Reflection 的设计思想对于处理复杂任务仍有必要。)
2. LangGraph 编排的本质
无论多么复杂的 Agent,信息编排流的核心都是:
- 节点 = 处理逻辑
- 边 = 信息流向
- State = 信息载体
3. 条件边的使用场景
- 需要判断时:用 Conditional Edge(如 should_continue)
- 无需判断时:用普通 Edge(如 tools→reflection)
相关资源
面试题
1. 什么是 Reflection?它解决什么问题?
Reflection(反思)是 Agent Loop 的经典范式,在 ReAct 的"思考→行动→反馈"循环基础上,引入一个 Critic/Reviewer 节点。它解决的问题是:ReAct 模型只负责完成任务,但不看完成的结果,导致输出质量不可控。Reflection 让模型在提交结果前先进行"复盘",由 Reviewer 判断是否需要打回重新修改。
2. Reflection 的工作流程是什么?
Task → Think → Action → Observation → Critic → [打回 Think | 输出 End]
- 模型完成任务后,优先将结果输送给 Critic
- Critic 拿原始任务和已完成信息进行对比
- Critic 判断:打回给模型重新修改,还是直接输出
3. LangGraph 编排的四步走是什么?
- 定义节点:明确每个节点的职责是什么
- 加入节点:将节点添加到 graph
- 编排边:编辑节点间的信息流向
- 类型对齐:确保发送和接收的数据类型一致(统一使用 state)
4. 如何用条件边实现 should_continue 逻辑?
def should_continue(state: AgentState) -> str:
if last_message_has_tool_calls(state):
return "tools"
else:
return "END"
遍历消息队列,检查最后一条消息是否包含 tool_calls 属性:有则返回 "tools" 指向工具节点,无则返回 "END" 直接输出。
5. Reflection 在 LangGraph 中如何实现连边?
# 1. start → agent
graph.add_edge("start", "agent")
# 2. agent → tools 或 END(条件边)
should_continue = ConditionalEdge("agent", ...)
graph.add_edge(should_continue)
# 3. tools → reflection
graph.add_edge("tools", "reflection")
# 4. reflection → agent
graph.add_edge("reflection", "agent")
6. 为什么需要设置最大循环次数?
防止 Agent 在 Reflection 判断逻辑出现偏差时进入无限循环。例如模型一直无法通过 Reviewer 的审核、或者 Reflection 给出的指引始终让模型继续执行,需要设置上限(如 12 次)来保护系统。
7. Agent Node 和 Tools Node 的职责分别是什么?
- Agent Node:接收用户任务,执行大模型推理,根据 system prompt 生成思考结果和工具调用指令
- Tools Node:解析 Agent 输出的工具调用,执行具体工具逻辑,将执行结果添加到 state 并返回
8. ReAct 和 Reflection 的核心区别是什么?
| 维度 | ReAct | Reflection |
|---|---|---|
| 节点数 | 3 个(start/agent/tools/end) | 4 个(+ reflection) |
| 反馈机制 | 无 | 模型自检 |
| 模型数量 | 1 个 | 2 个(agent + reviewer) |
| 执行流程 | 单向循环 | 增加打回机制 |