author: 盒子里的agent source: 小红书 url: https://www.xiaohongshu.com/discovery/item/6a18eb46000000003603141b?app_platform=ios&app_version=9.25&share_from_user_hidden=true&xsec_source=app_share&type=normal&xsec_token=CBxLMlImNgSFEE4VUT7WEFKtNLwl5BVRJ3sSKKTcfclp4=&author_share=1&xhsshare=WeixinSession&shareRedId=ODY7Nzs8ND02NzUyOTgwNjY0OTc5Sz85&apptime=1780118761&share_id=080942a89ce14517b2fd0ef570e461cf saved: 2026-05-30 13:26:47 tags: - 笔记同步助手
id: d609ce23-e559-42dd-87d8-247b6542babb
作者: 盒子里的agent
发布/编辑时间: 2026年05月29日 01:26
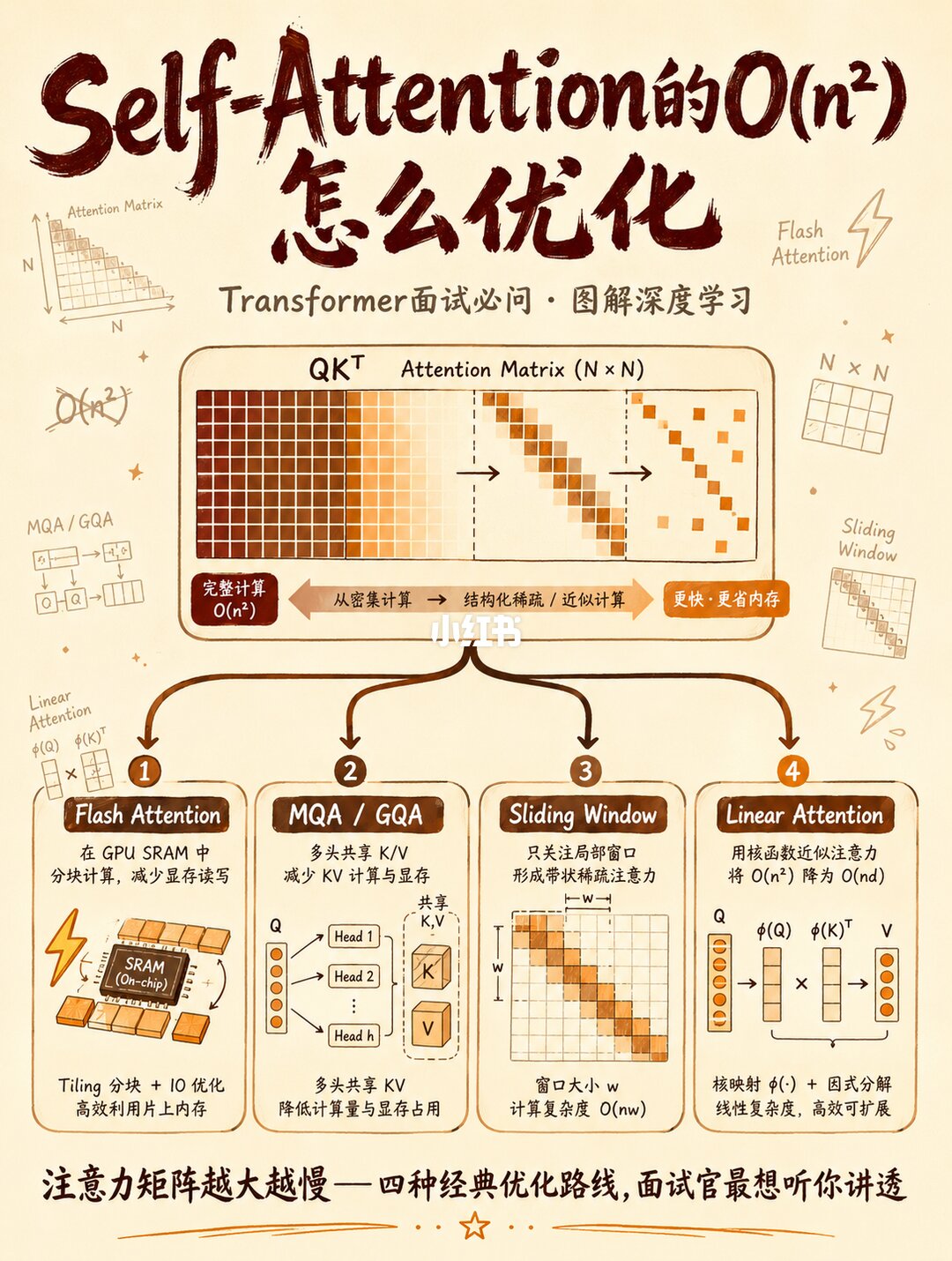
Transformer面试被问"self-Attention的O(n²)怎么优化"怎么答?⚡
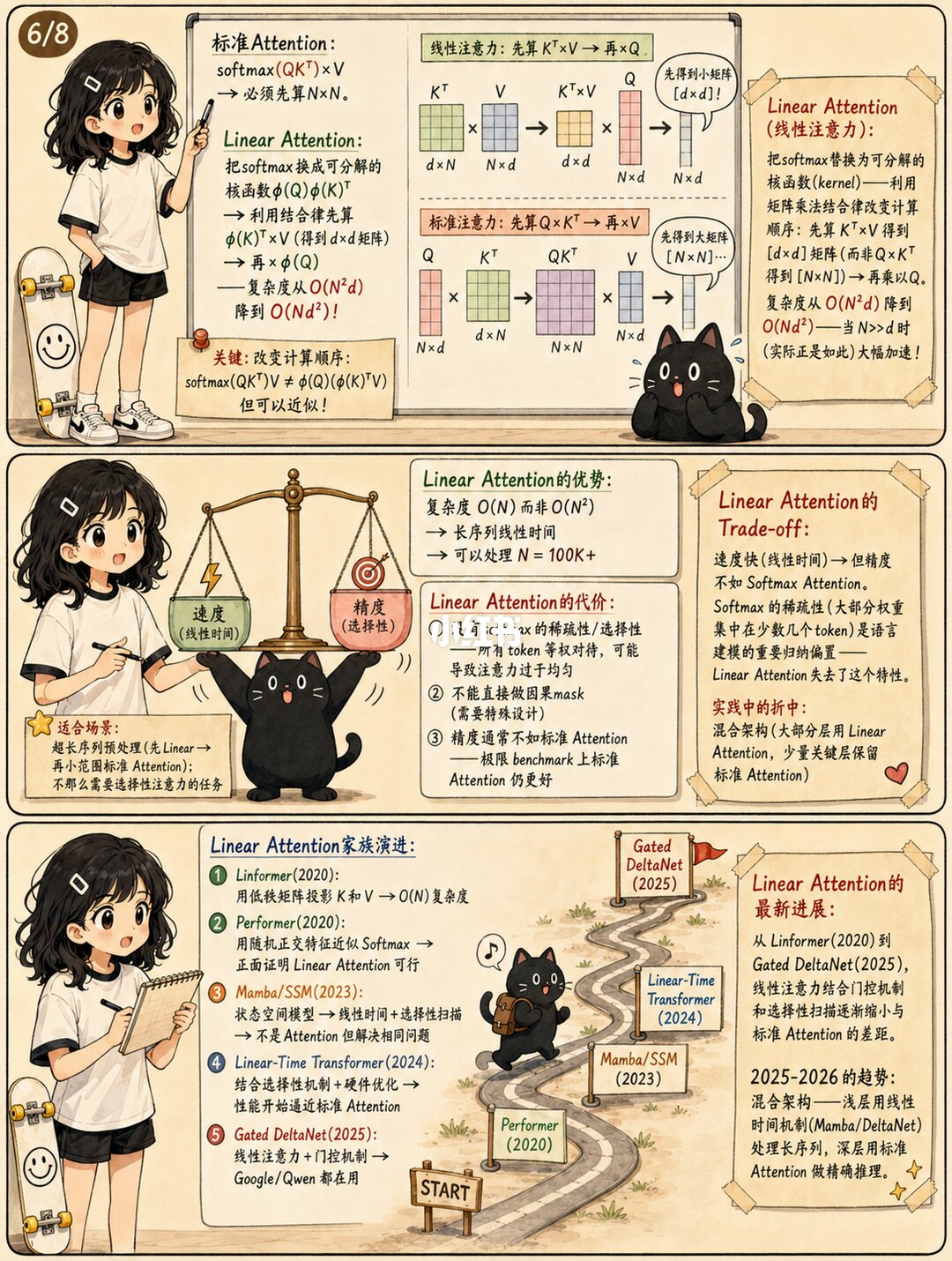
1️⃣ QK^T产生N×N矩阵→时间和显存都是O(n²)→N=32K时单层吃8GB显存
2️⃣ Flash Attention用Tiling把计算留在GPU SRAM→显存降到O(n),2-4倍加速
3️⃣ MQAu002FGQA让多头共享Ku002FV→KV Cache减少4-8倍,LLaMAu002FDeepSeek标配
4️⃣ 实战没有一个LLM只用标准Attention——都是组合拳:Flash Attn+GQA+稀疏
面试三层递进:定位问题→四种方案→实战组合📝
#transformer #LLM #大模型入门 #大模型面试 #大模型入门 #深度学习 #attention #deepseek #ai面试






内容效果不满意?点此反馈